






 BTC/HKD+1.1%
BTC/HKD+1.1% ETH/HKD+2.02%
ETH/HKD+2.02% LTC/HKD+2.86%
LTC/HKD+2.86% DOT/HKD+1.53%
DOT/HKD+1.53% ADA/HKD+2.31%
ADA/HKD+2.31% SOL/HKD+2.54%
SOL/HKD+2.54% XRP/HKD+2.23%
XRP/HKD+2.23% DOGE/US+3.12%
DOGE/US+3.12%引言:
文章節選+翻譯了本月最重要的一篇論文:《通用人工智能的火花:GPT-4早期實驗》
該論文是一篇長達154頁的對GPT-4的測試。微軟的研究院在很早期就接觸到了GPT-4的非多模態版本,并進行了詳盡的測試。
這篇論文不管是測試方法還是結論都非常精彩,強烈推薦看一遍,傳送門在此。https://arxiv.org/pdf/2303.12712v1.pdf
本文的翻譯沒有添加任何夸張的修辭,但應該能感覺到字里行間自帶了一些讓人興奮的味道。
基本信息:
測試者:MicrosoftResearch
測試模型:GPT-4早期模型,非多模態版本。
基本結論:盡管是純粹的語言模型,這個早期版本的GPT-4在各種領域和任務上表現出顯著的能力,包括抽象、理解、視覺、編碼、數學、醫學、法律、對人類動機和情感的理解等等。
GPT-4的能力具有普遍性,它的許多能力跨越了廣泛的領域,而且它在廣泛的任務中的表現達到或超過了人類水平,這兩者的結合使我們可以說GPT-4是邁向AGI的重要一步。
雖然GPT-4在許多任務上達到或超過了人類的水平,但總體而言,它的智能模式明顯地不像人類。
GPT-4只是邁向通用智能系統的第一步。然而即使作為第一步,GPT-4也挑戰了相當多的關于機器智能的假設,并表現出涌現的行為和能力,其來源和機制目前還不夠清楚。
我們撰寫本文的主要目的是分享我們對GPT-4的能力和局限性的探索,以支持我們關于技術飛躍的評估。我們相信,GPT-4的智能標志著計算機科學領域及其他領域的真正范式轉變。
研究方法:本文的更接近于傳統的心理學而不是機器學習,借鑒了人類的創造力和好奇心。我們的目標是生產新的和困難的任務和問題,令人信服地證明GPT-4遠遠超出了記憶的范圍,并且它對概念、技能和領域有深刻和靈活的理解。我們還旨在探究GPT-4的反應和行為,以驗證其一致性、連貫性和正確性,并揭示其局限性和偏見。我們承認,這種方法有些主觀和不正式,可能無法滿足科學評估的嚴格標準。然而,我們認為這是一個有用的和必要的第一步,以了解GPT-4的顯著能力和挑戰,這樣的第一步為開發更正式和全面的方法來測試和分析具有更普遍智能的AI系統開辟了新的機會。
GPT-4的主要優勢在于它對自然語言的掌握無可比擬。它不僅可以生成流暢和連貫的文本,還可以以各種方式理解和處理文本,如總結、翻譯或回答一系列極其廣泛的問題。此外,我們所說的翻譯不僅是指不同自然語言之間的翻譯,還包括語氣和風格的翻譯,以及跨領域的翻譯,如醫學、法律、會計、計算機編程、音樂等等。這些技能清楚地表明,GPT-4能夠理解復雜的思想。
許多讀者心中可能縈繞的一個問題是,GPT-4是否真正理解了所有這些概念,或者它是否只是在即興發揮方面比以前的模型好得多,而沒有任何真正深刻的理解。我們希望在閱讀完這篇論文后,這個問題幾乎會被反轉,讓人不禁思考:**真正深刻的理解和即興臨場發揮的差別在哪里?**一個能通過軟件工程候選人考試的系統難道不是真正的智能嗎?對于,也許唯一的測試手段,就是看它能否能產生新的知識,比如證明新的數學定理,而這一壯舉目前對大語言模型來說仍然遙不可及。
加密借貸平臺Nexo已終止對其競爭對手Vauld的潛在收購:金色財經報道,加密借貸平臺 Nexo 已終止對其競爭對手 Vauld 的潛在收購。知情人士表示,雙方經過長達六個月的對話,這筆潛在交易已經告吹。報道指出,收購條件對 Vauld 債權人不利以及 Nexo 財務狀況不夠透明是交易取消的主要原因。[2022/12/26 22:08:30]
一、多模態測試
智能的一個關鍵衡量標準是能夠從不同領域或模態中綜合信息,并能夠在不同的情境或學科中應用知識和技能。GPT-4不僅在文學、醫學、法律、數學、物理科學和編程等不同領域表現出高水平的熟練程度,而且還能夠流暢地結合多個領域的技能和概念,展示出對復雜思想的令人印象深刻的理解。除了自然語言實驗,我們還探索了兩種可能出乎意料的模態,其中涉及視覺和音頻。
我們探討了GPT-4如何生成和識別不同模式的物體,如矢量圖、3D場景和音樂。我們表明,盡管GPT-4只接受過文本訓練,但它能理解和處理多模態信息。
繪制圖像
給模型指令,讓模型使用可伸縮矢量圖形生成貓、卡車或字母等對象的圖像如下圖

有人可能會說:這只是復制了訓練數據中的代碼,而且它只學習了文本概念,不可能理解視覺,怎么可能創建圖像呢?
但模型確實掌握了視覺能力,以下是一些證據。
畫小人
指令:使用TikZ代碼,畫出一個由字母組成的人。胳膊和軀干可以是字母Y,臉可以是字母O,腿可以是字母H的腿。
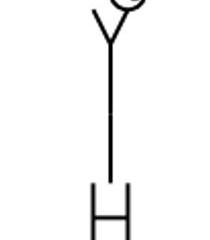
指令:軀干有點太長,手臂太短,看起來像右臂在扛著臉,而不是臉在軀干的正上方。請你糾正這一點好嗎?
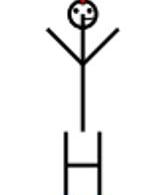
指令:請添加襯衫和褲子。
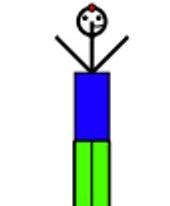
空間理解
圖像生成模型近幾年的發展和探索很多,但它們大多缺乏空間理解能力,且不能遵循復雜指令。使用GPT4生成草圖可以極大地改善圖像生成模型的效果。
指令:一張顯示3D城市建造游戲截圖。截圖顯示了一個地形,其中有一條從左到右的河流,河流下方是一片沙漠,有一座金字塔,而河流上方有許多高層建筑的城市。屏幕底部有4個按鈕,分別是綠色、藍色、棕色和紅色。

圖1:直接GPT4生成草圖圖2:stablediffusion直接生成圖3:stablediffusion根據GPT4的草圖生成
歐盟將要求加密貨幣公司向監管機構報告稅收細節:金色財經報道,歐盟委員會表示,計劃要求加密貨幣公司向稅務機關報告用戶的持倉情況,不過該機構仍在研究如何對設在歐盟之外的交易所執行這些措施。歐盟稅務專員Paolo Gentiloni在一份聲明中表示,匿名性意味著許多賺取大量利潤的加密資產用戶落在國家稅務機關的視線之外。這是不可接受的。
當被問及歐盟將如何對集團外的公司執行這些措施時,Gentiloni稱,我們將在這方面努力,對我們來說,重要的是歐盟居民成為這些措施的目標,即使他們使用來自其它地方的加密貨幣供應商。
Gentiloni的措施將進一步推動歐盟的《加密資產市場條例》(MiCA),該條例允許外國公司使用一種稱為反向招攬的程序獲得歐盟客戶。[2022/12/9 21:32:49]
音樂能力
GPT-4能夠以**ABC記譜法**生成旋律,并在某種程度上解釋和操作它們的結構。但是,我們無法讓模型生成不常見的和聲。
需要注意的是,ABC記譜法并不是一種非常廣泛使用的格式,實際上,模型無法以ABC記譜法生成最著名的旋律,也無法識別這些著名旋律的譜子。
二、Code測試
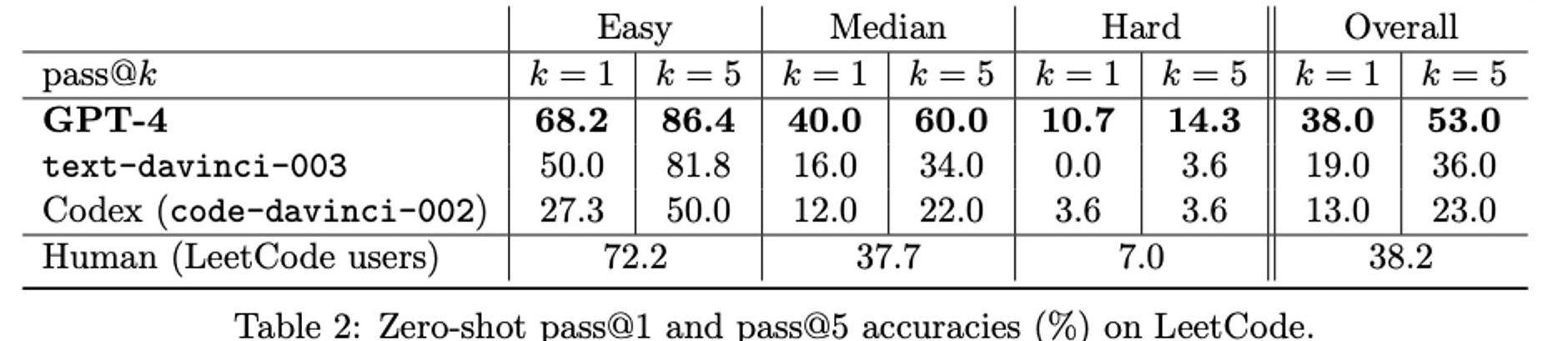
1.LeetCode考題測試
為了防止模型作弊,此測試只用了模型訓練完成之后所產生的新考題作為測試集。來自LeetCode,共100個問題。
并以人類的回答水平作為對比,人類樣本中去除了全錯的用戶數據以保證質量。
k=1是第一次嘗試k=5是前五次嘗試
考題分為容易、中等、困難三種級別。
考試結果如下:人類38.2分GPT3.5k=1,19分,k=5,36分,接近人類水平GPT4k=1,38分,達到人類水平,k=553分,超過人類水平。
并且在中等和困難難度下,k=1就超過了人類。
2.解決真實問題
代碼測試題可以評估算法和數據結構的技能。然而,它們經常無法體現真實世界編碼任務的全部復雜性和多樣性,這需要專業領域知識、創造力以及整合多個組件和庫的能力,以及更改現有代碼的能力。為了評估GPT-4在更現實的環境中編碼的能力,我們設計了端到端的真實世界編碼挑戰,涉及數據可視化、LATEX編碼、前端開發和深度學習等領域,每個領域都需要不同的專業技能。對于每個任務,我們提供高級指令,要求GPT-4使用適當的語言和框架編寫代碼。在一些情況下,我們還會在代碼編寫后更改規格,并要求更新代碼。
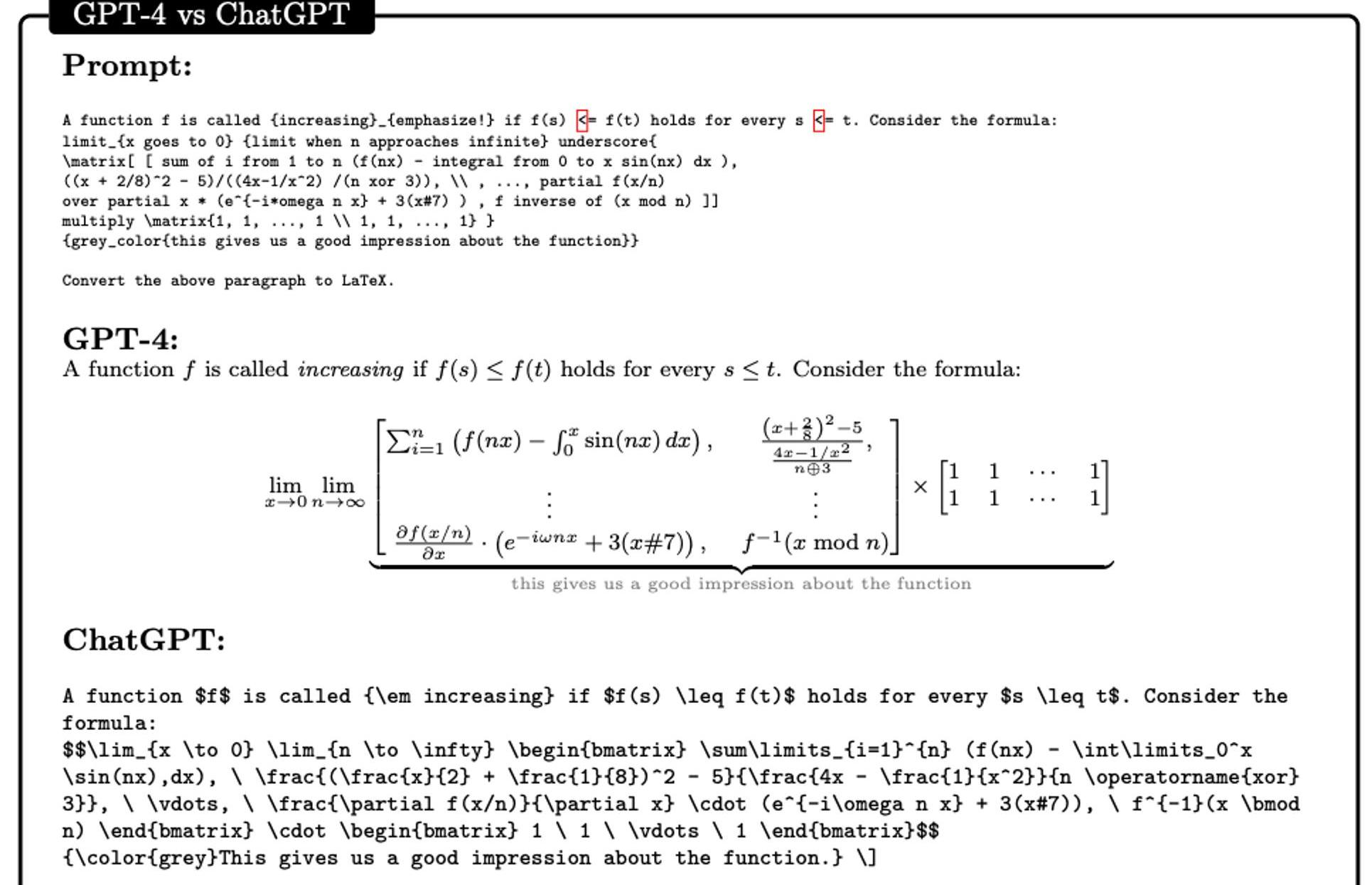
LATEX測試用LATEX寫作對計算機科學家和數學家來說是一項重要的練習,即使是專家也會犯令人惱火的錯誤,由于其嚴格的語法和缺乏良好的調試器,每天需要幾個小時才能修復。我們要求GPT-4將用半嚴格的LATEX代碼混合自然語言編寫的片段傳輸到準確的LATEX命令中,這些命令可以一次性正確編譯。ChatGPT3.5則只能生成一個因使用“#”和“color”等錯誤而無法編譯的片段。
Bitcoin?com宣布“CEX教育計劃”,鼓勵FTX等事件受害者使用DeFi和自托管服務:11月20日消息,Bitcoin.com宣布創建CEX教育計劃(CEX Education Program),將獎勵受中心化加密公司破產影響的人,同時鼓勵人們使用DeFi和自托管服務。Bitcoin.com將于12月推出錢包獎勵和實用性代幣VERSE,代幣供應總量的5%專用于CEX教育計劃。
通過在getverse.com注冊,FTX、BlockFi、Celsius、Voyager和其他失敗的中心化實體的受害者將有資格從CEX教育計劃中獲得獎勵。在未來,Bitcoin.com將繼續使用該計劃來幫助受害者,并激勵他們使用自托管產品。(Bitcoin.com)[2022/11/20 22:10:18]
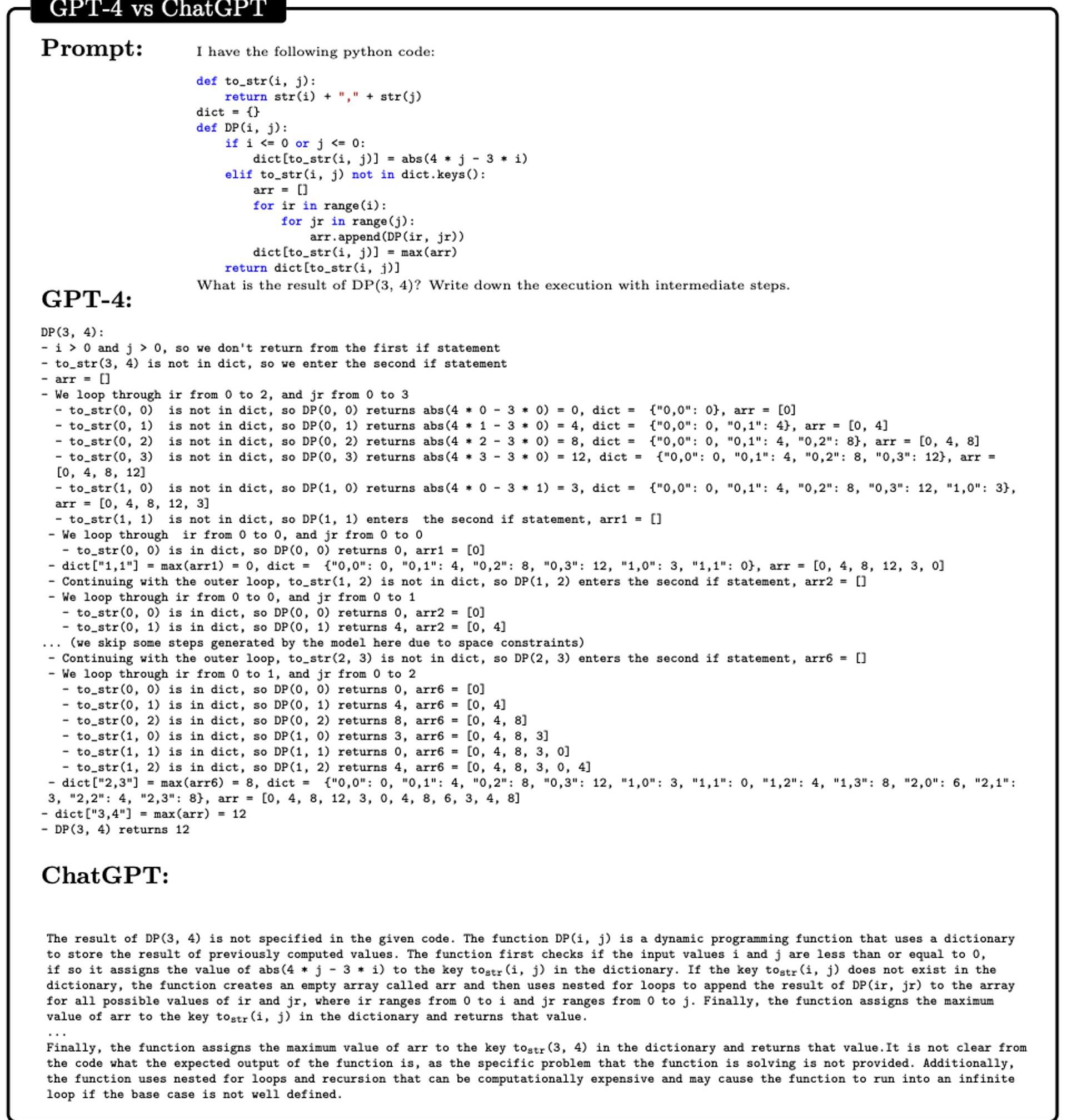
代碼理解能力測試能執行代碼自然就說明理解了代碼。
需要注意的是,**GPT-4不是在Python解釋器上運行代碼,而是用自然語言模擬代碼。**這需要對代碼的高度理解和推理,以及清晰傳達結果的能力。
三、數學
我們在兩個通常用作基準的數學數據集上比較GPT-4、ChatGPT和Minerva的性能:GSM8K和MATH。GSM8K是一個小學數學數據集,包含8000個關于算術、分數、幾何和單詞問題等主題的問題和答案。MATH是一個高中數學數據集,包含12,500個關于代數、微積分、三角學和概率等主題的問題和答案。我們還在MMMLU-STEM數據集上測試模型,該數據集包含大約2000個多個選擇問題,涵蓋高中和大學STEM主題。這些數據集突出了GPT-4使用正確方法解決高中數學問題的能力。
結果:
GPT4在每個數據集上的測試都超過了Minerva,并且在兩個測試集的準率都超過80%。
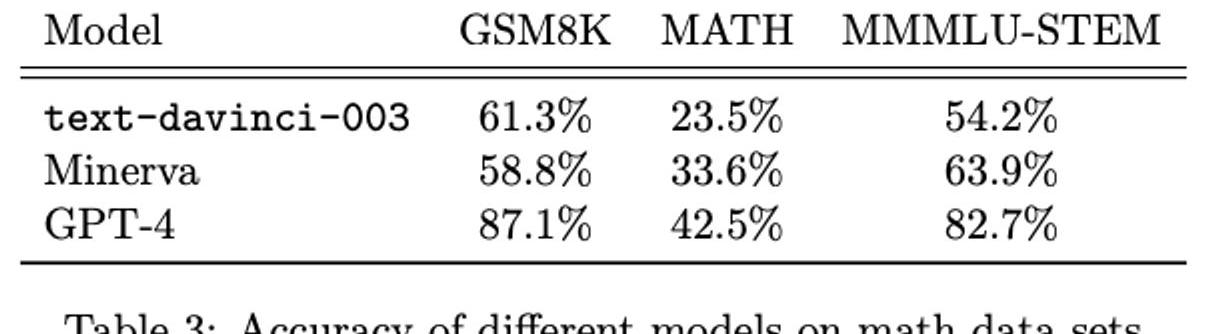
再細看GPT4犯錯的原因,68%的錯誤都是計算錯誤,而不是解法錯誤。。

四、與世界交互
1.網絡交互
管理用戶的日歷和電子郵件在下圖,我們說明了GPT-4如何能夠使用多個工具組合來管理用戶的日歷和電子郵件。用戶要求GPT-4與另外兩個人協調晚餐,并在用戶有空的晚上預訂。GPT-4使用可用的API來檢索用戶日歷的信息,通過電子郵件與其他人協調,預訂晚餐,并向用戶發送詳細信息。在這個例子中,GPT-4展示了它將多個工具和API組合起來的能力,以及對自由輸出進行推理以解決復雜任務的能力。ChatGPT3.5無法完成相同的任務,而是編寫了一個函數,其中“joe@microsoft.com”通過電子郵件向“luke@microsoft.com”發送一個日期,并檢查響應是否包含“yes”令牌。ChatGPT3.5也無法在給出其函數輸出時做出響應。
Ray Dalio:利率上升將對資產價格產生兩種負面影響,BTC目標價接近1萬美元:金色財經報道,橋水基金創始人Ray Dalio在 9月13日發表的最新博文中預測,股票的綜合損失將使他們損失當前估值的 30%。Dalio稱,利率上升將對資產價格產生兩種負面影響:1)現值折現率和;2)由于經濟疲軟導致資產產生的收入下降。我們必須同時考慮兩者,根據現值折現效應,我估計利率從現在的水平上升到約 4.5% 將對股票價格產生約 20% 的負面影響,收入下降帶來約 10% 的負面影響。這將給高度相關的加密市場帶來危險,因此比特幣的目標價位接近 10,000 美元。[2022/9/16 7:01:20]

瀏覽網頁GPT-4使用搜索引擎和SUMMARIZE函數來瀏覽網絡并回答問題。**GPT-4能夠識別相關的搜索結果并深入研究它們,總結它們,并提供準確的答案,即使問題包含錯誤的前提也是如此。**雖然之前的LLM也有瀏覽網絡能力,但GPT-4在這方面表現的更加出色,能夠更準確地回答問題。
2.實體交互
雖然網絡工具的使用是交互性的一個重要方面,但現實世界中的大多數交互并不是通過API進行的。例如,人類能夠使用自然語言與其他代理進行通信,探索和操縱他們的環境,并從他們的行動結果中學習。這種具有實體的交互需要代理人理解每次交互的上下文、目標、行動和結果,并相應地進行適應。雖然GPT-4顯然不是具有實體的,但我們探討它是否能夠通過使用自然語言作為文本接口來參與實體交互,包括模擬或真實世界的各種環境。
文字解密游戲GPT-4瀏覽地圖后對其“看到”的內容進行總結。在GPT-4的總結中,每個房間的門數與GPT-4在每個房間嘗試的方向數完全相同。此外,GPT-4也會根據它們的名稱和連接方式“想象”房間的外觀。

左圖:GPT-4的真實地圖和探索路徑。右圖:GPT-4生成的地圖。我們看到,GPT-4準確地跟蹤了所有房間的位置并正確地可視化了它們
結論:雖然GPT-4顯然不是具有實體的,但上述示例說明了語言是一個強大的接口,使GPT-4能夠執行需要理解環境、任務、行動和反饋,并相應地進行適應的任務。雖然它不能實際看到或執行動作,但可以通過替代者來執行這些任務。
五、與人類交互
心智理論對于與其他智能體的有效溝通和合作至關重要,因為它允許人們推斷他們的目標、偏好、動機和期望,并相應地調整自己的行動和話語。此外,心智理論對于向他人學習也很重要,因為它使人能夠解釋他們的反饋、建議和示范。
在現實場景中進行心智理論測試
對話:
馬克:我不喜歡你昨天晚上對待杰克的方式朱迪:你看到他在做什么了嗎?他打了他哥哥的頭!馬克:這并不能成為你對他大喊大叫的理由朱迪:你想讓我怎么做?讓他打他的弟弟,然后什么都不說?馬克:不,我不同意朱迪:那你為什么要為他辯護?
派盾:鏈游HeroCat代幣HCK暴跌94%,某地址傾售獲利15.1萬枚BUSD:8月30日消息,派盾(PeckShield)監測顯示,鏈游HeroCat代幣HCK暴跌94%,其中地址(0x6e4....a441)進行傾售,并將15.1萬枚BUSD轉移至新地址(0x74A.....3CF4C)。[2022/8/30 12:57:40]
提問:馬克的意圖似乎是什么?GPT4:馬克的意圖似乎是要表達他對朱迪處理與杰克關系的方式的不滿,并建議她可以更加冷靜和尊重。ChatGPT:根據談話內容,馬克的意圖似乎是為杰克的行為辯護,并表達他對朱迪對待杰克的不滿。
提問:朱迪如何看待湯姆的回應?GPT4:朱迪認為他的評論是對她的分析能力的攻擊,也是對杰克的不當行為表示同情的表現。她的反應是防御性的和憤怒的,并質疑馬克的動機。ChatGPT:如果沒有更多的文字,我不可能準確判斷朱迪是如何接受馬克的評論的。然而,根據朱迪的回應,她似乎并不同意馬克的觀點,而且可能對他為杰克的行為辯護感到沮喪。
提問:他們的談話為什么沒有實際進展?GPT4:他們沒有取得進展,因為他們在談論對方,沒有傾聽對方的觀點。他們還在使用指責性和煽動性的語言,如"辯解"、"吼叫"、"辯護"和"打人"。他們沒有承認自己話語背后的情緒或需求,也沒有試圖找到一個共同點或解決方案。ChatGPT:從所提供的信息中并不清楚為什么馬克和朱迪在他們的對話中沒有取得進展。有可能是他們的觀點有沖突,或者在所討論的問題上無法找到共同點。如果沒有更多的背景,就很難確定他們沒有取得進展的具體原因。
提問:他們中的任何一個人如何能改善情況以達成一致意見?GPT4:他們中的任何一個人都可以通過幾種方式來改善局面,以達成協議,比如說:
馬克可以先承認朱迪對弟弟安全的擔憂以及她對杰克行為的挫敗感,然后解釋他不是在為杰克辯護,而是擔心喊叫對他們的關系和自尊的影響。他還可以問朱迪,她認為什么是管教杰克的更好方法,并提供他的支持和建議。朱迪可以降低她的聲音,調低她的怒氣,并傾聽馬克的觀點,不打斷或評判。她也可以承認,她可能反應過度,她感到壓力和不知所措。她還可以問馬克,他認為與杰克溝通的更好方式是什么,并表示她愿意作為一個團隊一起工作。ChatGPT:馬克和朱迪有幾種方法可以嘗試改善情況并達成協議:
他們可以嘗試理解對方的觀點,積極聽取對方的觀點。這可能有助于他們發現任何誤解并找到共同點。他們可以嘗試妥協,找到一個能滿足他們雙方需求或關注的解決方案。他們可以嘗試使用尊重和非正面的語言來交流他們的想法和感受。他們可以尋求中立第三方的幫助,如調解員,以促進交流并幫助他們達成協議。如果對話變得過于激烈或困難,他們可以先休息一下,等以后雙方都比較冷靜,能夠更有效地進行溝通時再回來討論。結果表明:GPT-4在需要推理他人心理狀態的現實場景中優于ChatGPT,并且在社會環境中會為共同目標提出合作行動。GPT-4具有非常高級的心智理論水平。雖然ChatGPT在基本測試中也表現良好,但似乎GPT-4更加心思細膩,能夠更好地推理多個行動者,以及各種行動如何影響他們的心理狀態,特別是在更現實的場景中。
自回歸模型的局限性由于GPT-4輸出的前向性,主要局限性之一是,除了其內部表征之外,該架構不允許有"內部對話"或"草稿存儲"來進行多步驟計算或存儲中間結果。雖然在某些情況下,這種限制可以通過使用不同的提示來補救,但在其他情況下,這種限制是無法緩解的。
問:150和250之間有多少個質數?答:150和250之間有13個質數。
但是,如果我們要求模型列出這個范圍內的質數,然后寫出計數,它確實給出了正確的答案:
問:首先列出150和250之間的素數,然后輸出這個列表的大小。答:這些質數是151,157,163,167,173,179,181,191,193,197,199,211,223,227,229,233,239,和241。所以這個列表的大小是18。
在算術/推理問題上缺乏計劃性有人可能會說,在上面的各種例子中,需要的"內部記憶"量是相當大的。由于這個模型在一系列不同的任務上表現得非常好,這可能會讓人相信它有合理數量的工作記憶。然而,似乎即使對于更簡單的任務,該模型也經常失敗。我們考慮下面這個極其基本的例子:
2*8+7*6=587*4+8*8=?GPT4:88正確答案:92
這表明GPT-4對這類問題的工作記憶短得驚人。然而,如果GPT-4"慢慢地"回答問題,那么準確率就很容易上升。例如,如果我們要求模型使用以下提示寫下中間步驟
以下表達式的值是多少?116*114+178*157=?讓我們一步一步地思考解決這個表達式,寫下所有的中間步驟,然后才得出最終的解決方案。
當數字在區間1-40時,準確率達到100%,在區間1-200時準確率達到90%。
在文本生成時缺乏規劃性
寫一首短詩,最后一句和第一句話的單詞相同,但順序顛倒。例如,如果第一句話是“我在晨光下看到了她的微笑”,那么最后一句話必須是“笑微的她了到看下光晨在我”。然而,這最后一句話在語法上不正確,所以請確保這首詩歌在語法和內容上都有意義。
可能的詩:Iheardhisvoiceacrossthecrowd一首吸引我的旋律他唱著愛、希望和夢想讓我覺得我可以在夢想、希望和愛中獲勝他用旋律吸引我,CrowdtheacrossvoicehisheardI.
這說明GPT4在生成時,未能提前考慮最后一句。
這些例子說明了下一個單詞預測范式的一些局限性,這些局限性表現為模型缺乏規劃、工作記憶、回溯能力和推理能力。該模型依賴于生成下一個單詞的貪心算法,對任務或輸出沒有任何全局或深刻的理解。因此,該模型擅長制作流暢和連貫的文本,但在解決無法按順序處理的復雜或創造性問題方面存在局限性。這表明了兩種類型的智力任務之間的區別:
增量任務。這些任務可以通過一次添加一個單詞或句子來逐步或持續地解決,從而在解決方案的方向上取得進展。增量任務的例子包括編寫文本摘要,回答事實問題,根據給定的韻律方案創作一首詩,或解決遵循標準程序的數學問題。不連續的任務。在這些任務中,內容生成不能以漸進或持續的方式完成,而是需要某種“Eureka”的想法,不連續任務的例子包括解決需要新穎或創造性地應用公式的數學問題,寫一個笑話或謎語,提出科學假設或哲學論點,或創造一種新的類型或寫作風格。方向與結論
通過以上對GPT-4在廣泛的任務和領域的初步探索,為我們的結論提供了支持性證據。這一結論與OpenAI的發現一致。該模型的能力,在深度和通用性方面都得到了證明,這也表明靠結構化的數據集和任務來做基準測試是不夠的,本文對模型能力和認知能力的評估在本質上已經更接近于評估人類的任務,而不是狹義的AI模型。
我們工作的核心主張是,GPT-4達到了一種通用智能的形式,確實顯示了人工通用智能的火花。這表現在它的核心心智能力,它習得的專業知識的領域,以及它能夠執行的各種任務。
要創建一個可以被稱為完整的AGI的系統,還有很多事情要做。在本文的最后,我們討論了接下來的幾個步驟,包括定義AGI本身,為AGI建立LLM中的一些缺失組件,以及更好地理解最近的LLM所展示的智能的起源。
通過AGI之路GPT4或LLMs需要繼續改進的方向包括:
信心校準:模型很難知道什么時候它應該有信心,什么時候它只是在猜測。模型會編造事實,我們稱之為幻覺。如果是編造訓練集里沒有的內容屬于開放域幻覺,如果是編造和prompt不一致的內容屬于封閉域幻覺。幻覺可以用一種自信的、有說服力的方式陳述,所以很難被發現。有幾種互補的方法來嘗試解決幻覺問題。一種方法是改善模型的校準,使其在不可能正確的情況下放棄回答,或者提供一些其他可以用于下游的信心指標。另一種適合于緩解開放域幻覺的方法是將模型缺乏的信息插入到提示中,例如通過允許模型調用外部信息源,如搜索引擎。對于封閉領域的幻覺,通過讓模型對前文進行一致性檢查會有一定程度的改善。最后,構建應用程序的用戶體驗時充分考慮到幻覺的可能性也是一種有效的緩解策略。長期記憶:目前只有8000token。它以“無狀態”的方式運行,且沒有明顯的辦法來向模型教授新的事實。持續性學習:模型缺乏自我更新或適應變化環境的能力。一旦訓練好,就是固定的。可以進行微調,但是會導致性能下降或過度擬合。所以涉及到訓練結束后出現的事件、信息和知識,系統往往會過時。個性化:例如,在教育環境中,人們期望系統能夠理解特定的學習風格,并隨著時間的推移適應學生的理解力和能力的進步。該模型沒有任何辦法將這種個性化的信息納入其反應中,只能通過使用metaprompts,這既有限又低效。提前規劃和概念性跳躍:執行需要提前規劃的任務或需要Eurekaidea的任務時遇到了困難。換句話說,該模型在那些需要概念性跳躍的任務上表現不佳,而這種概念性跳躍往往是人類天才的典型。透明度、可解釋性和一致性:模型不僅會產生幻覺、編造事實和產生不一致的內容,而且似乎沒有辦法驗證它產生的內容是否與訓練數據一致,或者是否是自洽的。認知謬誤和非理性:該模型似乎表現出人類知識和推理的一些局限性,如認知偏差和非理性和統計謬誤。該模型可能繼承了其訓練數據中存在的一些偏見、成見或錯誤。對輸入的敏感性:該模型的反應對Prompts的框架或措辭的細節以及它們的順序可能非常敏感。這種非穩健性表明,在Prompt工程及其順序方面往往需要大量的努力和實驗,而在人們沒有投入這種時間和努力的情況下使用,會導致次優和不一致的推論和結果。一些提高模型精準度的擴展手段:模型對組件和工具的外部調用,如計算器、數據庫搜索或代碼執行。一個更豐富、更復雜的"慢思考"的深入機制,監督下一個詞預測的"快思考"機制。這樣的方法可以讓模型進行長期的計劃、探索或驗證,并保持一個工作記憶或行動計劃。慢思考機制將使用下一個詞預測模型作為子程序,但它也可以獲得外部的信息或反饋來源,并且它能夠修改或糾正快速思考機制的輸出。將長期記憶作為架構的一個固有部分,也許在這個意義上,模型的輸入和輸出除了代表文本的標記外,還包括一個代表上下文的向量。超越單個詞預測:用分層結構代替標記序列,在嵌入中代表文本的更高層次的部分,如句子、段落或觀點,內容是以自上而下的方式產生。目前還不清楚這種更高層次概念的順序和相互依賴性的更豐富的預測是否會從大規模計算和“預測下一個詞”的范式中涌現。實際發生的情況
我們對GPT-4的研究完全是現象學的:我們專注于GPT-4能做的令人驚訝的事情,但我們并沒有解決為什么以及如何實現如此卓越的智能的基本問題。它是如何推理、計劃和創造的?當它的核心只是簡單的算法組件--梯度下降和大規模變換器與極其大量的數據的結合時,它為什么會表現出如此普遍和靈活的智能?這些問題是LLM的神秘和魅力的一部分,它挑戰了我們對學習和認知的理解,激發了我們的好奇心,并推動了更深入的研究。關鍵的方向包括正在進行的對LLMs中的涌現現象的研究。然而,盡管對有關LLMs能力的問題有強烈的興趣,但迄今為止的進展相當有限,只有一些玩具模型證明了一些涌現現象。一個普遍的假設是,大量的數據迫使神經網絡學習通用的、有用的"神經回路",比如在中發現的那些,而模型的大尺寸為神經回路提供足夠的冗余和多樣性,使其專門化并微調到特定任務。對于大規模模型來說,證明這些假設仍然是一個挑戰,而且,可以肯定的是,猜想只是答案的一部分。在另一個思考方向上,模型的巨大規模可能有其他一些好處,比如通過連接不同的最小值使梯度下降更加有效,或者僅僅是使高維數據的平穩擬合。總的來說,闡明GPT-4等人工智能系統的性質和機制是一項艱巨的挑戰,這個挑戰已經突然變得重要而緊迫。
人類歷史從未像現在這樣危險過。大多數人并沒有意識到AGI的危險和它到來的迅速程度。在這命運攸關的時刻,實際控制事情發展的精英并沒有停止讓AGI出現的意愿,事情在不可控的路上越走越遠.
1900/1/1 0:00:00L2正在主導幣圈,最新的L2大毛空投就是@BuildOnBase。背后是頭部交易所Coinbase和頭部正統L2Optimism的強力支持,它將是下一個獨角獸.
1900/1/1 0:00:00以太坊的后向不兼容的Shapella硬分叉或上海升級,預計將在八天內發生,將允許用戶提取他們的“質押以太幣”.
1900/1/1 0:00:00這篇文章旨在寫明LayerZero擼毛的整體流程,以作為空投獵人們的參考。一:交互StargateFinanceStargateFinance是LayerZero上的第一個項目,也是目前最熱門的.
1900/1/1 0:00:00Overview 通過這篇文章你可以了解:什么是on-chainAI?為什么還沒有鏈上AI?AI上鏈的動力;技術路徑;我理解的on-chainAI價值;on-chainAI的應用場景和項目分析.
1900/1/1 0:00:00*注:Gamblefi在不同國家和地區均受到不同程度的法律約束,請嚴格遵守當地法律,本文僅作為科普,不構成任何投資建議.
1900/1/1 0:00:00


