






 BTC/HKD-4.02%
BTC/HKD-4.02% ETH/HKD-4.25%
ETH/HKD-4.25% LTC/HKD-2.09%
LTC/HKD-2.09% DOT/HKD-4.97%
DOT/HKD-4.97% ADA/HKD-6.41%
ADA/HKD-6.41% SOL/HKD-9.05%
SOL/HKD-9.05% XRP/HKD-5.92%
XRP/HKD-5.92% DOGE/US-6.6%
DOGE/US-6.6%導讀
首先問大家一個小問題?區塊鏈的賬本數據存儲格式主要是什么類型的?
相信聰明的你一定知道是Key-Value類型存儲。
下一個問題,這些Key-Value數據在底層數據庫如何高效組織?
答案就是我們本期介紹的內容:LSM。
LSM是一種被廣泛采用的持久化Key-Value存儲方案,如LevelDB,RocksDB,Cassandra等數據庫均采用LSM作為其底層存儲引擎。
據公開數據調研,LSM是當前市面上寫密集應用的最佳解決方案,也是區塊鏈領域被應用最多的一種存儲模式,今天我們將對LSM基本概念和性能進行介紹和分析。
LSM-Tree背景:追本溯源
LSM-Tree的設計思想來自于一個計算機領域一個老生常談的話題——對存儲介質的順序操作效率遠高于隨機操作。
如圖1所示,對磁盤的順序操作甚至可以快過對內存的隨機操作,而對同一類磁盤,其順序操作的速度比隨機操作高出三個數量級以上,因此我們可以得出一個非常直觀的結論:應當充分利用順序讀寫而盡可能避免隨機讀寫。
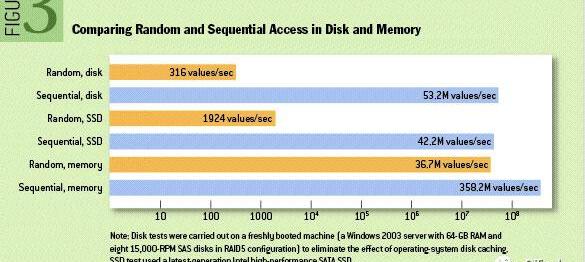
Figure1Randomaccessvs.Sequentialaccess
川渝高院將共同利用區塊鏈等技術 深度與訴訟服務進行融合:近日,四川省高級人民法院和重慶市高級人民法院采用遠程音視頻聯調方式簽署《成渝地區雙城經濟圈跨域訴訟服務合作協議》,根據協議內容,兩地法院將共同拓展人工智能、大數據、區塊鏈等新興技術與訴訟服務的深度融合,建立智慧服務共建共享機制。
四川省高級人民法院副院長張能表示,本次“云簽約”所采用的區塊鏈存證技術,尤其是音視頻存證、電子協議存證,是未來川渝兩地跨域訴訟服務合作的一次技術性“試水”。 他表示,未來在川渝地區一系列跨域訴訟服務合作的開展, 都將以此為技術支撐循序展開。[2020/9/19]
考慮到這一點,如果我們想盡可能提高寫操作的吞吐量,那么最好的方法一定是不斷地將數據追加到文件末尾,該方法可將寫入吞吐量提高至磁盤的理論水平,然而也有顯而易見的弊端,即讀效率極低,我們稱這種數據更新是非原地的,與之相對的是原地更新。
為了提高讀取效率,一種常用的方法是增加索引信息,如B+樹,ISAM等,對這類數據結構進行數據的更新是原地進行的,這將不可避免地引入隨機IO。
LSM-Tree與傳統多叉樹的數據組織形式完全不同,可以認為LSM-Tree是完全以磁盤為中心的一種數據結構,其只需要少量的內存來提升效率,而可以盡可能地通過上文提到的Journaling方式來提高寫入吞吐量。當然,其讀取效率會稍遜于B+樹。
山東省人力資源和社會保障廳:利用區塊鏈技術 實現電子檔案材料的分散式存儲:山東省人力資源和社會保障廳探索實現退休審核由“現場面對面”到“掌上不見面”轉型,推動“掌上辦”“零跑腿”“不見面”“無紙化”變革,并運用區塊鏈技術實現電子檔案材料的分散式存儲,經技術識別后導入核心平臺,審核業務隨時可查詢、永久可回溯。(齊魯網)[2020/5/8]
LSM-Tree數據結構:抽絲剝繭
圖2展示了LSM-Tree的理論模型(a)和一種實現方式(b)。LSM-Tree是一種層級的數據結構,包含一層空間占用較小的內存結構以及多層磁盤結構,每一層磁盤結構的空間上限呈指數增長,如在LevelDB中該系數默認為10。
Figure2LSM與其LevelDB實現
對于LSM-Tree的數據插入或更新,首先會被緩存在內存中,這部分數據往往由一顆排序樹進行組織。
當緩存達到預設上限,則會將內存中的數據以有序的方式寫入磁盤,我們稱這樣的有序列為一個SortedRun,簡稱為Run。
隨著寫入操作的不斷進行,L0層會堆積越來越多的Run,且顯然不同的Run之前可能存在重疊部分,此時進行某一條數據的查詢將無法準確判斷該數據存在于哪個Run中,因此最壞情況下需要進行等同于L0層Run數量的I/O。
為了解決該問題,當某一層的Run數目或大小到達某一閾值后,LSM-Tree會進行后臺的歸并排序,并將排序結果輸出至下一層,我們將一次歸并排序稱為Compaction。如同B+樹的分裂一樣,Compaction是LSM-Tree維持相對穩定讀寫效率的核心機制,我們將會在下文詳細介紹兩種不同的Compaction策略。
聲音 | 江蘇省司法廳:引入區塊鏈等先進技術 推進精準法律援助:據江南時報消息,近日,江蘇省司法行政系統信息化工作會議要求,打造智慧法務,推動全系統工作模式由經驗管理型向智慧引領型轉變。通過區塊鏈技術的融合應用,解決信息共享交換的突出問題,實現“不見面辦理公證”。參照公證做法,引入區塊鏈等先進匹配的技術,提升部門數據交換的效率,推進精準法律援助。[2018/9/17]
另外值得一提的是,無論是從內存到磁盤的寫入,還是磁盤中不斷進行的Compaction,都是對磁盤的順序I/O,這就是LSM擁有更高寫入吞吐量的原因。
Levelingvs.Tiering:一讀一寫,不分伯仲
LSM-Tree的Compaction策略可以分為Leveling和Tiering兩種,前者被LevelDB,RocksDB等采用,后者被Cassandra等采用,稱采用Leveling策略的的LSM-Tree為LeveledLSM-Tree,采用Tiering的LSM-Tree為TieredLSM-Tree,如圖3所示。
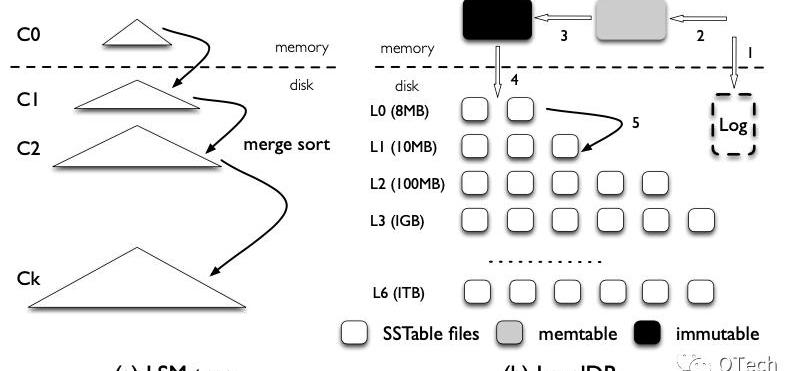
Figure3兩種Compaction策略對比
▲Leveling
簡而言之,Tiering是寫友好型的策略,而Leveling是讀友好型的策略。在Leveling中,除了L0的每一層最多只能有一個Run,如圖3右側所示,當在L0插入13時,觸發了L0層的Compaction,此時會對Run-L0與下層Run-L1進行一次歸并排序,歸并結果寫入L1,此時又觸發了L1的Compaction,此時會對Run-L1與下層Run-L2進行歸并排序,歸并結果寫入L2。
聲音 | 陳偉星:區塊鏈是促進集體主義的技術 讓社會經濟關系可編程:7月12日消息,陳偉星剛剛發布微博稱:“區塊鏈是促進集體主義的技術,讓社會經濟關系可編程;發幣就是當公務員,必須以建立公信為原則。貪污、私吞公共資金、通過欺詐竊取老百姓利益,完全是區塊鏈精神背道而馳的。做區塊鏈技術,就是做防止造假的技術;宣傳區塊鏈精神,就是傳播信任,打擊造假的精神。這種“擋騙子財路”的行為,就是區塊鏈所有的行為,這就是區塊鏈時代與私有制公司行為最大的變革!”[2018/7/12]
▲Tiering
反觀Tiering在進行Compaction時并不會主動與下層的Run進行歸并,而只會對發生Compaction的那一層的若干個Run進行歸并排序,這也是Tiering的一層會存在多個Run的原因。
▲對比分析
相比而言,Leveling方式進行得更加貪婪,進行了更多的磁盤I/O,維持了更高的讀效率,而Tiering則相正好反。
本節我們將對LSM-Tree的設計空間進行更加形式化的分析。
LSM層數

布隆過濾器
LSM-Tree應用布隆過濾器來加速查找,LSM-Tree為每個Run設置一個布隆過濾器,在通過I/O查詢某個Run之前,首先通過布隆過濾器判斷待查詢的數據是否存在于該Run,若布隆過濾器返回Negative,則可斷言不存在,直接跳到下個Run進行查詢,從而節省了一次I/O;而若布隆過濾器返回Positive,則仍不能確定數據是否存在,需要消耗一次I/O去查詢該Run,若成功查詢到數據,則終止查找,否則繼續查找下一個Run,我們稱后者為假陽現象,布隆過濾器的過高的假陽率會嚴重影響讀性能,使得花費在布隆過濾器上的內存形同虛設。限于篇幅本文不對布隆過濾器做更多的介紹,直接給出FPR的計算公式,為公式2.
丹華資本張首晟:看好區塊鏈技術 呼吁大家關注歐洲區塊鏈的發展:丹華資本創始人、美圖獨立董事張首晟表示,看好區塊鏈技術,丹華資本非常關注區塊鏈,也投資了多家區塊鏈項目。對于中美區塊鏈項目發展的差異,張首晟表示,兩邊都做得很好,他強調,大家也要多關注歐洲區塊鏈的發展。[2018/3/25]
其中是為布隆過濾器設置的內存大小,為每個Run中的數據總數。讀寫I/O
考慮讀寫操作的最壞場景,對于讀操作,認為其最壞場景是空讀,即遍歷每一層的每個Run,最后發現所讀數據并不存在;對于寫操作,認為其最壞場景是一條數據的寫入會導致每一層發生一次Compaction。
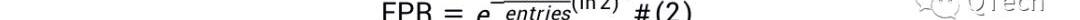
核心理念:基于場景化的設計空間
基于以上分析,我們可以得出如圖4所示的LSM-Tree可基于場景化的設計空間。
簡而言之,LSM-Tree的設計空間是:在極端優化寫的日志方式與極端優化讀的有序列表方式之間的折中,折中策略取決于場景,折中方式可以對以下參數進行調整:

當Level間放大比例時,兩種Compaction策略的讀寫開銷是一致的,而隨著T的不斷增加,Leveling和Tiering方式的讀開銷分別提高/減少。
當T達到上限時,前者只有一層,且一層中只有一個Run,因此其讀開銷到達最低,即最壞情況下只需要一次I/O,而每次寫入都會觸發整層的Compaction;
而對于后者當T到達上限時,也只有一層,但是一層中存在:

因此讀開銷達到最高,而寫操作不會觸發任何的Compaction,因此寫開銷達到最低。
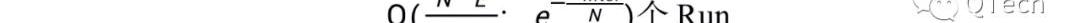
Figure4LSM由日志到有序列的設計空間
事實上,基于圖4及上文的分析可以進行對LSM-Tree的性能進一步的優化,如文獻對每一層的布隆過濾器大小進行動態調整,以充分優化內存分配并降低FPR來提高讀取效率;文獻提出“LazyLeveling”方式來自適應的選擇Compaction策略等。
限于篇幅本文不再對這些優化思路進行介紹,感興趣的讀者可以自行查閱文獻。
小結
LSM-Tree提供了相當高的寫性能、空間利用率以及非常靈活的配置項可供調優,其仍然是適合區塊鏈應用的最佳存儲引擎之一。
本文對LSM-Tree從設計思想、數據結構、兩種Compaction策略幾個角度進行了由淺入深地介紹,限于篇幅,基于本文之上的對LSM-Tree的調優方法將會在后續文章中介紹。
作者簡介葉晨宇來自趣鏈科技基礎平臺部,區塊鏈賬本存儲研究小組
參考文獻
.O’NeilP,ChengE,GawlickD,etal.Thelog-structuredmerge-tree(LSM-tree).ActaInformatica,1996,33(4):351-385.
.JacobsA.Thepathologiesofbigdata.CommunicationsoftheACM,2009,52(8):36-44.
.LuL,PillaiTS,GopalakrishnanH,etal.Wisckey:Separatingkeysfromvaluesinssd-consciousstorage.ACMTransactionsonStorage(TOS),2017,13(1):1-28.
.DayanN,AthanassoulisM,IdreosS.Monkey:Optimalnavigablekey-valuestore//Proceedingsofthe2017ACMInternationalConferenceonManagementofData.2017:79-94.
.DayanN,IdreosS.Dostoevsky:Betterspace-timetrade-offsforLSM-treebasedkey-valuestoresviaadaptiveremovalofsuperfluousmerging//Proceedingsofthe2018InternationalConferenceonManagementofData.2018:505-520.
.LuoC,CareyMJ.LSM-basedstoragetechniques:asurvey.TheVLDBJournal,2020,29(1):393-418.
2020年12月26日,由上海區塊鏈技術協會主辦的“快樂上鏈,幸福確權”2020上海區塊鏈年度盛典在激昂奮進的鑼鼓聲中拉開帷幕.
1900/1/1 0:00:00來自:NewsBTC,作者:Jordan編譯:PANews原標題:《比特幣站上2萬美元后,認為比特幣最多值7.4萬美元的模型靠譜嗎?》2020年12月16日,比特幣歷史性的突破20,000美元.
1900/1/1 0:00:00來源:證券日報網? 記者侯捷寧 1月19日,中國證券業協會發布消息稱,為推進科技監管能力建設,促進證券業數字化轉型,形成共建共治共享的行業數字生態,提升證券業服務效率和質量.
1900/1/1 0:00:001月10日,曾在全球最大對沖基金橋水擔任分析師一職的HowardWang撰文直言,比特幣就是一個巨大的泡沫,現在來看,很難預測其頂部.
1900/1/1 0:00:00AMBcrypto今日刊文分析稱,PayPal等支付巨頭的支持,有望推動比特幣支付成為主流。然而,比特幣價格迅速上漲,對采用比特幣計價的支付系統構成了嚴峻的挑戰.
1900/1/1 0:00:001月11日,以太坊創始人V神發布《為什么我們需要廣泛采用社會恢復錢包》一文,其中介紹了社會恢復錢包的技術、原理和價值。他在文章中表示,錢包安全性問題是非常重要,不應該被低估.
1900/1/1 0:00:00


