






 BTC/HKD+0.21%
BTC/HKD+0.21% ETH/HKD-0.38%
ETH/HKD-0.38% LTC/HKD+0.7%
LTC/HKD+0.7% DOT/HKD+3.42%
DOT/HKD+3.42% ADA/HKD-1.7%
ADA/HKD-1.7% SOL/HKD+0.87%
SOL/HKD+0.87% XRP/HKD-0.92%
XRP/HKD-0.92% DOGE/US+0.83%
DOGE/US+0.83%在《打破K/V存儲的性能瓶頸》中,我們提到區塊鏈中的數據可以分為「連續型數據」和「K/V型數據」,并對K/V型數據的特點及讀寫進行了闡述。我們以leveldb為例,了解到K/V數據在存儲時采用LSM-Tree的組織形式,存儲方式相對而言比較復雜,數據讀寫的復雜度也較高,且在數據量大的情況下會遇到性能下降的問題。針對這些問題,我們已經提出了一些優化思路,但這種數據格式讀寫的性能存在天然的缺陷。而優化思路里也提到,leveldb的歸并操作是為了讓SSLTable的key變得有序,說明有序的數據在讀寫方面有天然優勢。
區塊鏈中也有很多數據是有序的。因此,本文將重點討論連續型數據的特點和連續型數據的讀寫方式,并根據實際場景中會遇到的問題提出我們的優化思路。
連續型數據,顧名思義,最大的特點就是連續。我們可以把連續型數據當做一種特殊的K/V數據,只不過其key值是單調遞增的。
“那么在區塊鏈中,什么樣的數據是連續的呢?”
區塊鏈中有一個重要的概念:區塊號,就是單調遞增的。區塊鏈是一個賬本,記下來的賬是只增不減的,區塊也是不斷向后追加的。因此,以區塊號為單位存儲的數據就可以認為是連續型數據。在上一篇推文中,我們提到除了區塊數據以外,回執數據、修改集數據也是連續型數據,這是因為每一條回執,每一條世界狀態修改記錄,都對應于一筆交易,而交易是區塊的組成部分,因此這些數據也可以以區塊為單位來存儲。

任何數據存儲的目的都是為了查詢,因此我們在存儲連續型數據的同時,需要考慮對這些數據的查詢需求。一般來說,對于區塊和交易數據,會有以下查詢需求:
Bitstamp:將于8月29日在美國下架AXS、CHZ、MANA、MATIC、NEAR、SAND和SOL:8月8日消息,據官方公告,Bitstamp宣布出于監管等因素考慮,將從2023年8月29日起在美國暫停以下加密貨幣交易:AXS、CHZ、MANA、MATIC、NEAR、SAND和SOL。
為了確保交易暫停期間的平穩過渡,請用戶在2023年8月29日之前立即執行涉及受影響資產的買入或賣出訂單。在此截止日期之后,與AXS、CHZ、MANA、MATIC、NEAR、SAND和SOL相關的交易活動將在Bitstamp平臺上永久禁用。[2023/8/8 21:32:30]
1)給定一個區塊號,查詢對應的整個區塊數據;
2)給定一個區塊哈希,查詢對應的整個區塊數據;
3)給定一個交易哈希,查詢這筆交易的詳細信息;
面對這樣的查詢需求,我們在設計數據庫時需要考慮如何支持這些查詢。
▲?以太坊
連續型數據作為一種特殊的K/V型數據,自然也可以用K/V數據庫來存儲,例如以太坊就是這樣存的。在以太坊中,所有數據均存儲在leveldb中,區塊和交易相關的數據存儲方式如下:
(H)+BlockHash->BlockNumber
(h)+BlockNumber+(n)->BlockHash
(h)+BlockNumber+BlockHash->BlockHeader
(b)+BlockNumber+BlockHash->BlockBody
Meta元宇宙部門Reality Labs一季度虧損40億美元:4月27日消息,Meta元宇宙部門Reality Labs今年第一季度虧損了40億美元,且Meta預計不僅會持續全年虧損,今年的虧損還將超過2022年。但Meta首席執行官馬克·扎克伯格(Mark Zucker berg)表示,有關Meta正在遠離元宇宙的說法是錯誤的。此前報道,RealityLabs在2022年全年虧損總額達137億美元。(TheBlock)[2023/4/27 14:29:41]
(l)+TxHash->BlockNumber
區塊數據直接存儲在leveldb當中,以區塊號和區塊哈希為key來進行查詢。這樣的存儲方式很方便,可以根據區塊哈希或區塊號快速查詢到區塊內容。但這種方式存儲下,leveldb的數據量會很大,數據的讀寫速度也會受到影響。
▲?HyperledgerFabric
超級賬本也是使用鍵值對數據庫存儲檢索信息,但是額外使用了文件存儲系統管理區塊數據。通過內存映射文件的方式提高了數據查詢的性能,但在多個索引或撤消歷史記錄的功能上存在局限。對于Fabric的數據存儲來說,一般都包含兩種方式,如下圖所示:
?文件形式存儲,用于記錄交易日志信息,所有的交易都是有序地連接在一起;
?NoSQL形式存儲,使用LevelDB數據庫實現保存索引信息的歷史記錄。
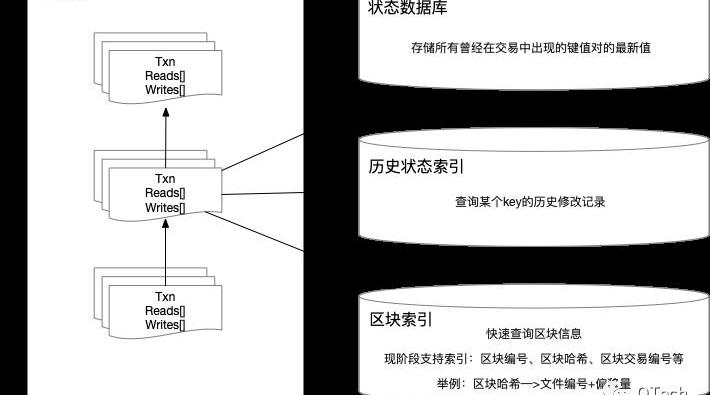
HyperledgerFabric中,賬本目錄中由blockfile_000000、blockfile_000001命名格式的文件名組成。為了快速檢索區塊數據,每個文件的大小是64M。每個區塊的數據都會序列化成字節碼的形式追加寫入blockfile文件中。在Fabric中,其索引組織格式如下:
ETH 2.0總質押數已超1773.76萬:金色財經報道,數據顯示,ETH 2.0總質押數已超1773.76萬,為17737642個,按當前市場價格,價值約311.22億美元。此外,目前ETH 2.0質押總地址數已超57.11萬,為571145個。[2023/3/25 13:25:31]
(h)+BlockHash->BlockLoc
(n)+BlockNumber->BlockLoc
(t)+len(TxID)+TxID+BlockNumber+TxNumber->TxIDIndexValue
這里的BlockLoc表示數據在哪個blockfile中以及其偏移量。在Fabric中要根據區塊號或區塊哈希查詢一個區塊,將先在leveldb中查詢索引,獲取BlockLoc之后在文件系統中查詢區塊。
相比于以太坊而言,Fabric將區塊數據存在文件中,大大降低了NoSQL數據庫的存儲壓力,且索引中直接標識數據位置,可以很快在文件中讀取到區塊數據。
事實上,無論是以太坊還是Fabric,都沒有完全利用連續型數據的特點:根據key值來計算偏移量。例如我們知道key為100的數據的位置,就能夠推斷出,key為200的數據與該位置相差100條數據,這個特點有利于我們快速查找數據。因此,根據偏移量的特點,我們可以進一步減少讀寫數據的開銷。

連續型數據庫的整體結構圖
BTC突破23900美元:金色財經報道,行情顯示,BTC突破23900美元,現報23907.1美元,日內漲幅達到3.76%,行情波動較大,請做好風險控制。[2023/1/30 11:35:56]
數據庫由多個logsegment組成,每一個logsegment由一個后綴為.log和一個后綴為.idx的文件組成,分別用于存儲數據和對應的索引數據。
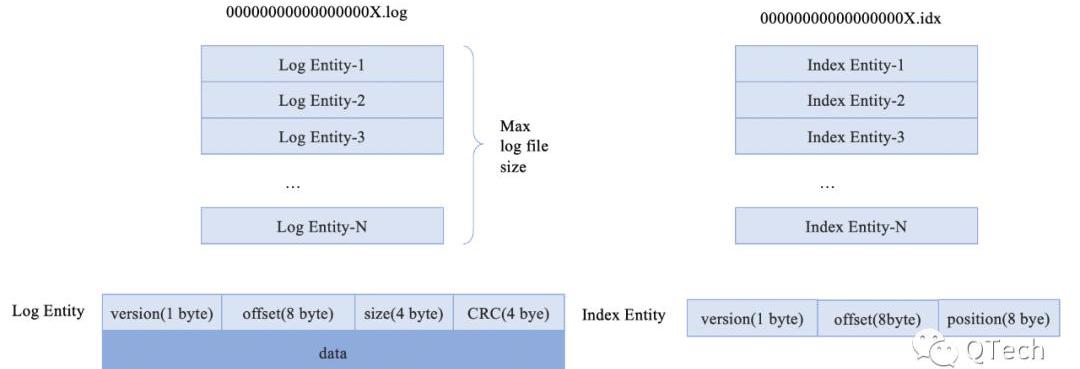
logsegment的結構圖
數據以文件的方式記錄到磁盤中,log為后綴的文件記錄原數據的信息,idx為后綴的文件記錄以log文件為單位的文件索引信息,用于快速定位需要查找的數據位置,每一個log文件都配套有一個相同前綴的idx文件。文件名前綴均為文件中存儲的第一條數據的偏移量數值。每一個log文件都有大小限制,當文件超過該限制時,新打開一個文件用于后續數據寫入。
我們采用logsegment里的第一條數據的key值作為文件名,也是利用到了數據有序這個特點,使用時間復雜度更低的二分查找來快速確認某一條數據位于哪個logsegment中。在這樣的數據結構下,數據的讀寫效率將變得非常高。
對于一次寫入操作,就根據數據構造一條LogEntity和一條IndexEntity,直接追加寫入到最后一個文件末尾即可。對于一次讀取操作,首先根據要讀取的數據的key值,使用二分查找找到該數據所在的log文件中,然后根據該key值相對于文件名的偏移量,計算索引所在位置。計算方式如下:
Chiliz創始人:已為FTX個人用戶分配3800萬枚CHZ用于補償:11月14日消息,Chiliz創始人Alexandre Dreyful在推特上表示,對于在FTX上持有CHZ的個人用戶,可獲得最高10,000美元的補償。該計劃不適用于機構,需要經過完整的法律審查和清算人的批準才能完成用戶補償名單。
據悉,Chiliz將在接下來的幾周內推進該計劃。此前Etherscan將該地址標記為“FTX”。[2022/11/14 13:00:59]
索引位置=偏移量*IndexEntitySize
其中IndexEntitySize的值是一個常量,在我們的設計里大小為17byte,偏移量表示key值相對于文件名的差值。通過計算,可以快速定位到當前key對應數據在文件中位置。通過位置信息,可以讀取IndexEntity,得到其中的position字段,找到log文件中的真實讀取位置,然后根據log字段中的size得到應該讀取的字節范圍。
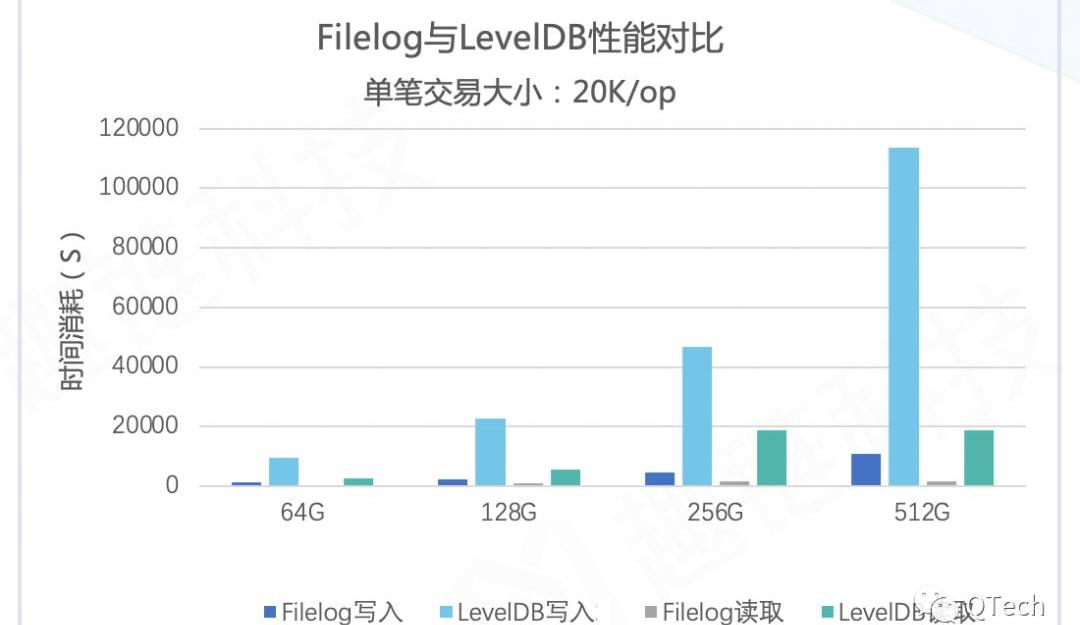
在這樣的設計之下,一次數據寫入操作只需要兩次磁盤IO,一次讀取操作只需要三次磁盤IO。相比于LeveDB復雜的數據組織格式,讀寫效率大大提高。此外,數據量的增大只會增加文件個數,即稍微增加二分查找的時間,但這點計算時間幾乎可以忽略不計,也就是說,該數據庫隨著數據的增大性能不會衰減。
下圖為我們設計的連續型數據庫相比于LevelDB,可以看出連續型數據庫的讀寫性能遠高于LevelDB。
設計這樣一個數據庫時,初衷是為了能更高效地存儲區塊數據,讓我們的平臺擁有更高的性能。隨著平臺逐漸成熟,我們也不斷完善數據庫,使其不僅讀寫效率高,還具有很好的魯棒性和健壯性,因此我們還從多個角度對我們的數據庫進行功能完善和優化,期望能夠適應更復雜的存儲環境以及更安全地存儲數據。
▲?句柄池
在數據庫使用過程中,不知道大家會不會經常遇到toomanyopenfiles的問題?那是因為,我們的操作系統對程序中可打開的「句柄數量」是有限制的。為了解決內存中打開的文件句柄過多的問題,更高效地利用句柄,我們引入了一種句柄池的機制來解決上述問題。句柄池的設置能夠保證單位時間內句柄的占用內存小,在并發讀取下也是線程安全的。
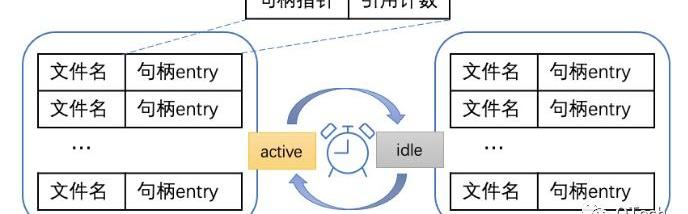
整體架構設計
圖中每個句柄entry維護文件名、句柄以及一個引用計數。我們用引用計數表示在當前時間,該句柄在多少個地方正在被使用。只有沒有進程在使用該句柄,即句柄引用計數為0的時候句柄才能被關閉。句柄池對外只提供句柄的申請與歸還接口。
實際使用過程中,句柄的申請和歸還是一個頻繁的并發操作,單個句柄池難以同時維護高并發情況下各個句柄的申請與歸還。例如剛好要清理句柄時,又出現了該句柄的申請請求,單個句柄池只能通過加讀寫鎖來控制并發,但這勢必會降低性能。因此句柄的打開和清理最好分離,所以我們句柄池的設計采用了兩個列表輪替的形式,其中一個處于活躍狀態,另一個處于清理狀態。活躍狀態的列表負責維護當前正在使用的句柄,而清理狀態的列表則負責將無用句柄關閉。新打開的句柄全部放入活躍列表中,清理列表則負責將所以引用計數為0的句柄關閉。當外部需要獲取句柄時,首先在句柄池中查看該句柄是否已經被打開:
如果已經打開,則將其引用計數加1;如果沒有打開,則打開句柄,也將引用計數加1,并把句柄放入活躍列表中;外部使用完畢后,歸還句柄至句柄池,即句柄的引用計數減1。每隔固定時間,數據庫將切換兩個列表,原本處于活躍狀態的列表將進入后臺進行清理,被清理過的列表則轉為活躍列表,負責下一階段里數據庫中要使用的句柄的維護。
與此同時,處于清理狀態的列表在后臺遍歷列表,對于引用計數為0的句柄進行關閉。這樣的設計能夠保證內存不會泄露的同時,更加高效地利用句柄,在頻繁讀取的情況下保證數據庫的性能。
▲?文件完整性
一般來說,成熟的數據庫都會保證存入數據的完整性,以防止數據庫被篡改或丟失數據卻不被發現。在區塊鏈系統中,這一點尤為重要。因此,在上述數據庫結構設計的基礎上,我們還設計了文件完整性的保證方案。數據庫在運行過程中會記錄數據狀態,當數據庫重啟時,我們會對數據狀態進行校驗,以防止數據被篡改。
單條數據的完整性我們已經通過CRC校驗碼保證了,但單個文件的完整性,我們需要設計其他的機制來保證。我們使用一個EDITLOG文件,用于持久記錄存儲文件發生的更改。當一個文件寫滿或者發生變更時,在該文件里追加寫入一條記錄。記錄的格式如下:
文件名變更類型哈希校驗碼CRC校驗碼
其中變更類別表示該條記錄對應的文件變更操作,由于數據庫支持數據歸檔,因而文件有可能會被新增、刪除或切分。
而哈希校驗碼,我們并沒有采用對整個文件內容進行哈希,而是采用對文件名、文件大小和文件修改時間這些信息做哈希計算。因為文件的內容較大,一次哈希的時間會很長,而事實上,防止文件損壞或被篡改,用這幾個文件屬性就可以基本滿足。
CRC校驗碼則進一步對對文件名和文件變化位計算CRC值,用于保證該條記錄不被修改。
本文是存儲系列推文的延續,對區塊鏈中連續型數據存儲的講解,著重介紹K/V型數據的存儲特點和優化思路,分析了連續型數據的特點,結合以太坊、Fabric存儲區塊和交易數據的模式,介紹我們設計的連續型數據存儲引擎。
通過研究發現,如果利用好連續型數據的特點,其讀寫效率將遠遠高于K/V型數據。由此受到啟發,在設計或選擇數據庫的時候,一定要分析我們需要存儲的數據特點,根據其特點來設計數據庫,才能將性能發揮到極致。
當然,我們在為區塊鏈設計特定的數據庫的同時,也希望該數據庫能夠更加完備與通用,因此也在以一個成熟數據庫的標準來優化拓展我們的功能,希望能夠應用在更多的場景中。
作者簡介
金鵬、王晨璐趣鏈科技基礎平臺部區塊鏈存儲研究小組
參考文獻
https://github.com/ethereum/go-ethereum
https://github.com/hyperledger/fabric
Tags:LOCLOCKBLOCBLOSherlockblockchaintechnologyGasBlockCrypto Legions Bloodstone
律動BlockBeats消息,9月27日,以太坊核心開發者TimBeiko在Github上公布了以太坊12月點網絡升級計劃,將僅包括「推遲難度炸彈」一項內容,不包含其他內容的升級.
1900/1/1 0:00:00據CoinDesk9月14日報道,美國食品藥品監督管理局周一宣布,三家區塊鏈公司成為該機構首屆年度食品可追溯性挑戰賽獲勝者.
1900/1/1 0:00:00Robinhood今年成長得如此之快,歸功于人們對狗狗幣的濃厚興趣。該交易平臺最近披露,Crypto交易占其今年第二季度收入的50%.
1900/1/1 0:00:00采訪及撰文:潘致雄受訪者:OffchainLabs首席執行官StevenGoldfeder和創始團隊以太坊擴容網絡ArbitrumOne正式上線且對外公開測試后.
1900/1/1 0:00:00據外媒9月16日報道,NFT市場在2021年出現了爆炸式增長,而一個數字收藏平臺于近日又獲得了一輪數百萬美元的融資.
1900/1/1 0:00:00▲?聯邦學習問題回顧 前文提及,于2016年,Google提出了用于訓練輸入法模型的新型方式,稱為「聯邦學習」.
1900/1/1 0:00:00


