






 BTC/HKD-0.07%
BTC/HKD-0.07% ETH/HKD+0.09%
ETH/HKD+0.09% LTC/HKD+0.59%
LTC/HKD+0.59% DOT/HKD+3.54%
DOT/HKD+3.54% ADA/HKD-2.11%
ADA/HKD-2.11% SOL/HKD+1.21%
SOL/HKD+1.21% XRP/HKD-1.39%
XRP/HKD-1.39% DOGE/US+1.09%
DOGE/US+1.09%撰文:Tanya Malhotra
來源:Marktechpost
編譯:DeFi 之道

圖片來源:由無界版圖AI工具生成
隨著生成性人工智能在過去幾個月的巨大成功,大型語言模型(LLM)正在不斷改進。這些模型正在為一些值得注意的經濟和社會轉型做出貢獻。OpenAI 開發的 ChatGPT 是一個自然語言處理模型,允許用戶生成有意義的文本。不僅如此,它還可以回答問題,總結長段落,編寫代碼和電子郵件等。其他語言模型,如 Pathways 語言模型(PaLM)、Chinchilla 等,在模仿人類方面也有很好的表現。
Crypto Exchange由于技術故障以6,000美元出售比特幣:2月26日消息,Crypto Exchange由于技術故障以6,000美元出售比特幣,是由于交易在過去幾個月中增長了70倍,這給交易所造成了沉重負擔,并導致其交易引擎在接縫處分裂。PDAX交易所首席執行官Nichel Gaba在一次新聞發布會上說,盡管“非常少的訂單”是有效的,但其中很多交易從未真正進行。(Decrypt)[2021/2/26 17:54:09]
大型語言模型使用強化學習(reinforcement learning,RL)來進行微調。強化學習是一種基于獎勵系統的反饋驅動的機器學習方法。代理(agent)通過完成某些任務并觀察這些行動的結果來學習在一個環境中的表現。代理在很好地完成一個任務后會得到積極的反饋,而完成地不好則會有相應的懲罰。像 ChatGPT 這樣的 LLM 表現出的卓越性能都要歸功于強化學習。
掌柜調查署 |? ChainUP Felix:ChainUP目前已經在KYC、AML等多環節進行了升級:在今日金色財經舉行主題為《交易所擁抱合規 ChainUP助力破局》的掌柜調查署中,針對“面對不同地區合規政策的不同,ChainUP又有哪些相應的“定制化”的服務和布局”的問題,ChainUP大客戶業務合伙人Felix表示,ChainUP的定制服務體現在三個方面:第一本土服務,在合規要求非常嚴格的日本和合規熱門地區新加坡,ChainUP都有非常好的本土服務,比如在日本有專門的分公司和本地化團隊,在總部新加坡也有很好政府關系,這些都可以更好的為客戶服務。第二是定制開發的系統,目前ChainUP已在KYC、AML、資金存儲及提現改造、當地政府對接審計報表/API、底層錢包存儲方案改造等環節完成多處升級。第三是跟歐美國家合規公司的合作。[2020/4/15]
ChatGPT 使用來自人類反饋的強化學習(RLHF),通過最小化偏差對模型進行微調。但為什么不是監督學習(Supervised learning,SL)呢?一個基本的強化學習范式由用于訓練模型的標簽組成。但是為什么這些標簽不能直接用于監督學習方法呢?人工智能和機器學習研究員 Sebastian Raschka 在他的推特上分享了一些原因,即為什么強化學習被用于微調而不是監督學習。
Dayli Blockchain收購Dayli Intelligence股份:韓國區塊鏈專業公司Dayli Blockchain為強化區塊鏈事業收購了Dayli Intelligence的10.23%股份,價值40億韓元(約人民幣2,300萬)。Dayli Intelligence是綜合金融科技公司Dayli金融集團中專注AI與區塊鏈的技術公司。[2018/6/19]
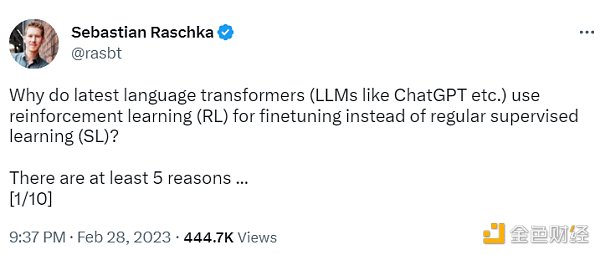
不使用監督學習的第一個原因是,它只預測等級,不會產生連貫的反應;該模型只是學習給與訓練集相似的反應打上高分,即使它們是不連貫的。另一方面,RLHF 則被訓練來估計產生反應的質量,而不僅僅是排名分數。
NEO投資瑞士區塊鏈個人數據交易平臺PikcioChain并計劃拓展中國市場:NEO投資瑞士區塊鏈個人數據交易平臺PikcioChain,通過購買了66萬個PikcioChain的PKC數字代幣,NEO投資了約300萬美元。PikcioChain計劃在NEO的支持下,積極拓展中國市場。[2018/1/24]
Sebastian Raschka 分享了使用監督學習將任務重新表述為一個受限的優化問題的想法。損失函數結合了輸出文本損失和獎勵分數項。這將使生成的響應和排名的質量更高。但這種方法只有在目標正確產生問題-答案對時才能成功。但是累積獎勵對于實現用戶和 ChatGPT 之間的連貫對話也是必要的,而監督學習無法提供這種獎勵。
不選擇 SL 的第三個原因是,它使用交叉熵來優化標記級的損失。雖然在文本段落的標記水平上,改變反應中的個別單詞可能對整體損失只有很小的影響,但如果一個單詞被否定,產生連貫性對話的復雜任務可能會完全改變上下文。因此,僅僅依靠 SL 是不夠的,RLHF 對于考慮整個對話的背景和連貫性是必要的。
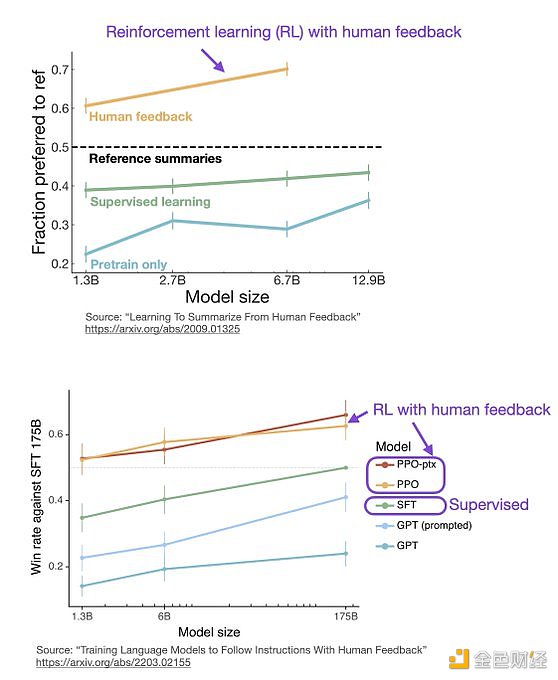
監督學習可以用來訓練一個模型,但根據經驗發現 RLHF 往往表現得更好。2022 年的一篇論文《從人類反饋中學習總結》顯示,RLHF 比 SL 表現得更好。原因是 RLHF 考慮了連貫性對話的累積獎勵,而 SL 由于其文本段落級的損失函數而未能很好做到這一點。
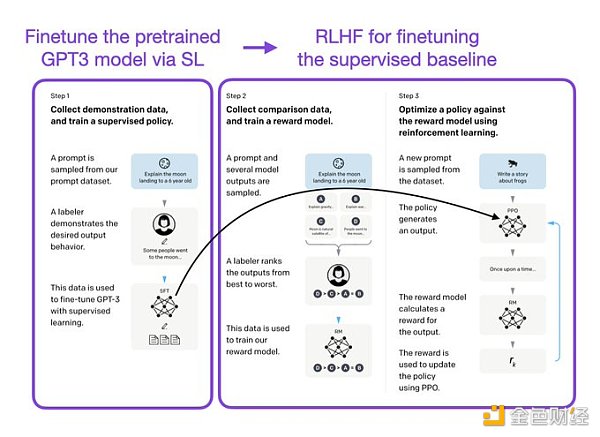
像 InstructGPT 和 ChatGPT 這樣的 LLMs 同時使用監督學習和強化學習。這兩者的結合對于實現最佳性能至關重要。在這些模型中,首先使用 SL 對模型進行微調,然后使用 RL 進一步更新。SL 階段允許模型學習任務的基本結構和內容,而 RLHF 階段則完善模型的反應以提高準確性。
DeFi之道
個人專欄
閱讀更多
金色財經 善歐巴
金色早8點
Odaily星球日報
歐科云鏈
Arcane Labs
MarsBit
深潮TechFlow
BTCStudy
澎湃新聞
Tags:CHAAINChainHAIThe Whale of BlockchainGPSChainbitpaychainonlychain
“我的這些反思將更多關注生存問題,包括L1生態系統的健康、捕獲、卡特爾、第二層與以太坊的對齊等等.
1900/1/1 0:00:00撰文:Louround 編譯:0x11,Foresight News上一輪牛市期間,我由于貪婪損失了 90% 的凈資產。一年半后,我的投資組合達到了歷史最高.
1900/1/1 0:00:00圖片來源:由無界版圖AI工具生成3月2日,OpenAI正式開放了ChatGPT的API接口,開發人員可以將ChatGPT模型集成到他們的應用程序和產品中.
1900/1/1 0:00:00來源:北京商報 自去年11月以來,加密貨幣的總市值下降了2/3,面臨著持續挑戰。但投資者對該行業的興趣仍然遠勝其他行業.
1900/1/1 0:00:00本文為對前沿有理 CFO Wing Tan 采訪內容整理1. 請介紹下前沿有理基金的歷史,現狀與未來發展規劃前沿有理資本(Fore Elite Capital)是由葉一舟 Ejoe Ye 先生于.
1900/1/1 0:00:00原文作者:Marco Manoppo這個系列文章將研究有趣的公司或協議,評估他們如何產生收入,估算他們的支出并分析其利潤.
1900/1/1 0:00:00


