






 BTC/HKD-0.66%
BTC/HKD-0.66% ETH/HKD-1.17%
ETH/HKD-1.17% LTC/HKD-0.41%
LTC/HKD-0.41% DOT/HKD-3.31%
DOT/HKD-3.31% ADA/HKD-2.03%
ADA/HKD-2.03% SOL/HKD-1.28%
SOL/HKD-1.28% XRP/HKD-2.68%
XRP/HKD-2.68% DOGE/US-2.3%
DOGE/US-2.3%原文標題:《從下一代數據中心的角度,談談為何 Web3 終將到來(10000 字 +)》
撰文:阿法兔;Shawn Chang,HardenedVault CEO
???本文試圖從數據中心進化的角度,探討數據中心從最早的機房時代逐步過渡到行業云背后市場和需求變化的原因,同時也從傳統業務和 Web3 業務的角度,思考了下一代數據中心呈現的狀態和進化背后的理由,除此之外,還從商業需求、社會文化、和目前看到的一些跡象來解釋為什么下一代數據中心會呈現分布式,最后對未來的業務形態進行了展望。
數據中心(Data Center),起源于 20 世紀 40 年代的巨型計算機房,以埃尼阿克這樣的最早面世的計算機為代表,早期的計算機系統,操作和維護起來很復雜,需要一個特殊的操作環境,連接所有組件需要許多電線和電纜,數據中心就是用來容納和組織這些組件的空間。

圖:最早的計算機埃尼阿克(ENIAC)來源:維基百科
在 20 世紀 80 年代,用戶可以在各個地方部署計算機,當時對操作的要求還并不復雜,但是,隨著信息技術 (IT) 運營的復雜度增加,大家意識到需要對 IT 資源進行控制。「數據中心」,適用于專門設計的計算機房。

1980 年代的數據中心長這樣,圖片來源
盡管 2000 年前后處于互聯網泡沫時期,很多公司倒閉,但是這段時間也給數據中心的發展和普及創造了機會,因為很多中小互聯網創業公司也需要快速的互聯網連接和不間斷的操作來部署系統,但是對于資源有限的小公司來說,安裝大型互聯網數據中心是很不實際的,因此許多公司開始建造非常大的設施,也就是 IDC(Internet Data Center,互聯網數據中心)

IDC 的發展經歷了三個不同階段:
第一代的數據中心只提供場地、帶寬等基礎托管服務;
第二代的數據中心則是以增值服務和電子商務作為其服務的核心;
第三代的數據中心能夠提供融合的托管服務,可以實時地將互聯網信息、電話信息、傳真信息等集成在一起,再以客戶最容易接受的方式提供給客戶,這樣,第三代的數據中心其實變成了一個網絡服務中心。
數據中心 1.0 時代,基本就是物理意義上的數據中心,也就是 1990 年代至 2006 年的機房時代,包含了大型計算機,小型計算機以及今天意義上的 x86 通用計算機,基本上就是電信企業面向大型企業提供的機房,包括場地、電源、網絡、通信設備等基礎電信資源和設施的托管和線路維護服務。
數據中心 2.0 時代,互聯網走向民用,網站數量激增,服務器、主機、出口帶寬等設備與資源集中放置與維護需求激增,主機托管、網站托管等商業模式出現,再到后來 IDC 服務商出現,他們圍繞主機托管提供數據存儲管理、安全管理、網絡互連、出口帶寬網絡服務等等,這一階段的數據中心由互聯網企業自行搭建或者租賃,存在建設與維護成本高、難以隨業務發展而靈活擴展諸多問題,云計算應運而生。2007 至 2013 的通用計算云時代,這一時期主要的特征是商業模式構建以租戶為中心,不論是物理機的服務器托管服務還是云計算的虛擬機租用模式。
數據中心 3.0 時代,2014 至 2021 的行業云時代,云服務提供商成為主流,而其中高價值的行業云誕生,數據中心的規模空前,而這也意味著計算和數據的高度的集中化。早在 1961 年就有人預料到計算會成為公共服務,1990 年代網格計算(Grid Computing)與云計算(Cloud Computing)等概念就已先后出現,不過直到本世紀初亞馬遜 AWS 才真正拉開云計算的序幕,計算真正成為所見即所得的公共服務,數據中心從分散在各地的「小電站」逐步走向集中式的「大電廠」,一般都是科技巨頭搭建的大型化、虛擬化、綜合化數據中心,通過對存儲與計算能力虛擬化,變為一種按需使用的計算力,對于使用者來說,集中規模化降低了成本,同時具備了靈活拓展能力。
與Ara攻擊者相關EOA地址已將294.9枚BNB轉入Tornado Cash:金色財經消息,據CertiK官方推特發布消息,與Ara攻擊者相關EOA地址(0x623) 已將294.9枚BNB轉入Tornado Cash。[2023/6/26 21:59:44]
數據中心的歷史,最早可以追溯到 20 世紀 40 年代中期,當時最早用于軍事的計算機房容納了大型軍用機器,用來處理特定的數據任務。到了 20 世紀 60 年代,有了大型計算機的誕生,IBM 公司為大型公司和政府機構部署了專用大型機房,但是,由于使用需求的增長,需要獨立的建筑承載這些大型計算機,這就是最早一批數據中心的誕生。
直到 20 世紀 80 年代,個人電腦(PC)橫空出世,電腦需要與遠程服務器聯網,這樣才可以訪問大型數據文件。到 20 世紀 90 年代,也就是互聯網(Web1.0)開始廣泛普及時,互聯網交換中心(IX)大樓已逐步在主要國際城市興起,以滿足萬維網的需求。這些 IX 大樓,也是是當時最重要的數據中心,很多人提供服務,很多還在使用。
主要是指是不同電信運營商之間為連通各自網絡而建立的集中交換平臺,互聯網交換中心在國外簡稱 IX 或 IXP,一般由第三方中立運營,是 互聯網的重要基礎設施。
隨著互聯網使用的增長,數據中心數量開始急劇上升,因為 2000 年前后,各種規模的公司都熱衷于在互聯網上建立自己的網站,這時的數據中心,可以為這些公司的網站提供托管服務,并且提供遠程服務器以保持它的運行。由于這個時候的互聯網數據中心有著大量的服務器和來自不同電話公司和網絡運營商的電纜,一旦網站出現任何技術問題,數據中心運營商可以馬上更換服務器或切換連接,以保持其正常運行。
當時,很多組織或者公司會將自己的數據業務遷移到數據中心,這種方式被稱為主機托管,也就是說,企業要么將自己的服務器放在供應商的數據中心,要么從供應商那里租用服務器空間,用于遠程運行和訪問一些應用程序,例如電子郵件、數據存儲或備份。
不過,在過去的十年左右,云服務大廠頻頻出現,無論是微軟、谷歌、亞馬遜、IBM、甲骨文、SAP、Salesforce、阿里云,還是其他許多公司,云服務的市場,最初是由亞馬遜網絡服務啟動的,該公司圍繞「基礎設施即服務(IaaS)」為企業提供托管解決方案。IaaS 允許公司通過云計算靈活地訪問由 AWS 等供應商擁有的遠程服務器,并根據其業務數據處理和管理需要,按需使用(也就是說,企業可以隨時點外賣,由專業服務商處理這些業務)。
還有一種說法是,AWS 提供 IaaS,主要是因為亞馬遜有著快速增長的電子商務業務,而這些業務可以為市場其他主體提供多余的云服務器容量,而事實并不是這樣,AWS 的出現,是亞馬遜可以向任何有需求的人或機構提供 IaaS 而專門建立的業務,IaaS 允許初創公司和小公司與大型機構競爭,因為大型機構通常擁有更廣泛的計算能力供其支配,有了云服務,小公司也可以直接采購成熟的業務,不需要自己建設團隊(自己建設團隊,構建計算能力的成本對于小公司是非常高的)
當很多公司開始通過云計算遠程訪問部分或大部分關鍵的商業軟件應用程序,而不是在位于自己機房的服務器上部署和管理這些應用時,云計算數據中心的增速就開始了。
成本和效率,永遠是商業公司需要考慮的。
有了云服務,無論是何種規模的公司,都可以根據業務需求,選擇合適的使用規模,從而降低軟件的成本。這比在公司內部服務器上永久安裝一些功能豐富的軟件的成本要低很多。
由于云服務的需求急劇增加,因此,為托管這些服務而建造的數據中心的規模和數量也會增加。這樣的數據中心就是超大規模的數據中心,通常這種設施由云服務提供商和其他公司所有,建造這些設施是為了向提供這些服務的家喻戶曉的公司使用空間。2020 年第二季度末,如微軟、谷歌和亞馬遜運營的全球大型數據中心總數已增加到 541 個,比 2015 年中期的數字增加了一倍多。
1980--2000 年這段區間內,互聯網剛出現,大型機和小型機是主流,但其成本非常高昂,運行的 UNIX 系統也成本高昂,并且,通用計算機 x86 性能尚且無法滿足很多業務需求,但是隨著通用計算機真正成為下一個時代的趨勢,降本增效成為了所有企業的剛性需求。
Immutable X 2月份NFT銷售額約2334萬美元:金色財經報道,據Cryptoslam數據顯示,2月Immutable X 上NFT銷售額達到約2334.43萬美元,創下自2022年10月以來最高單月記錄。[2023/3/2 12:38:35]
2000 年到現在,2006 年 AWS 成立是一個開始,之后行業逐步認可了公有云作為基礎設施的存在,特別是在 2013/2014 年,AWS 拿很多大客戶的單子,我們可以這么理解,在早年間使用公有云的確成本低廉,成本優勢巨大,但在 2015 之后公有云的成本優勢也在不斷減少,即使按照整體成本(服務器 + 租用機柜 + 運維人員工資 + 開發團隊協同等因素)目前公有云成本并不占優勢,于是出現了很多大廠開始自建云的趨勢。
那么,下一代數據中心長什么樣?和 Web3 有什么關系?為什么會出現新的第四代數據中心?背后的原因何在?
首先,我們認為下一代數據中心一定會與目前的數據中心不同,這是業務進化和底層技術的迭代所造成的必然。
其次,下一代數據中心,會呈現分布式(邦聯化)和去中心化的形態。
為什么這么判斷?
我們先從業務角度來看,這塊分為兩部分:一是傳統業務,二是 Web3 業務。
首先,如果從傳統業務來看,Service Mesh 的發展,給很多業務帶來了分布式的呈現。自從幾十年前第一次引入分布式系統這個概念以來,出現了很多原來根本想象不到的分布式系統使用案例,行業的需求特推動著前進的步伐,分布式系統的組成從幾個大型的中央電腦發展成為數以千計的小型服務。具體是怎么回事呢?
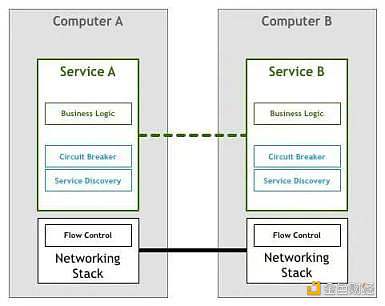
首先,當電腦第一次聯網,由于人們首先想到的是讓兩臺或多臺電腦相互通訊,因此,大家構思出了如下圖的邏輯。
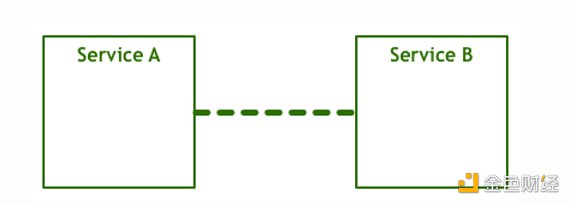
互相之間可以通訊的兩個服務可以滿足最終用戶的一些需求,讓我們把這個圖再詳細一點,添加一些網絡協議棧組件:
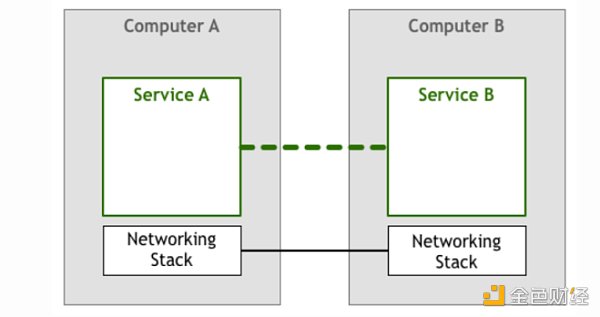
上述這個修改過的模型自 20 世紀 50 年代以來一直使用至今。一開始,計算機很稀少,也很昂貴,所以兩個節點之間的每個環節都被精心制作和維護。隨著計算機變得越來越便宜,連接的數量和數據量大幅增加。隨著人們越來越依賴網絡系統,工程師們需要保證他們構建的軟件能夠達到用戶所要求的服務質量。當然,還有許多問題急需解決以達到用戶要求的服務質量水平。人們需要找到解決方案讓機器互相發現、通過同一條線路同時處理多個連接、允許機器在非直連的情況下互相通信、通過網絡對數據包進行路由、加密流量等等。
在這其中,有一種叫做流量控制的東西,下面我們以此為例。流量控制是一種防止一臺服務器發送的數據包超過下游服務器可以承受上限的機制。這是必要的,因為在一個聯網的系統中,你至少有兩個不同的、獨立的計算機,彼此之間互不了解。計算機 A 以給定的速率向計算機 B 發送字節,但不能保證 B 可以連續地以足夠快的速度來處理接收到的字節。例如,B 可能正在忙于并行運行其他任務,或者數據包可能無序到達,并且 B 可能被阻塞以等待本應該第一個到達的數據包。這意味著 A 不僅不知道 B 的預期性能,而且還可能讓事情變得更糟,因為這可能會讓 B 過載,B 現在必須對所有這些傳入的數據包進行排隊處理。
一段時間以來,大家寄希望于建立網絡服務和應用程序的開發者能夠通過編寫代碼來解決上面提出的挑戰。在我們的這個流程控制示例中,應用程序本身必須包含某種邏輯來確保服務不會因為數據包而過載。在我們的抽象示意圖中,它是這樣的:
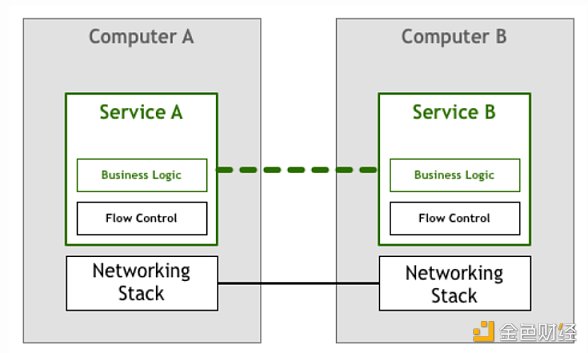
幸運的是,技術的發展日新月異,隨著像 TCP/IP 這樣的標準的橫空出世,流量控制和許多其他問題的解決方案被融入進了網絡協議棧本身。這意味著這些流量控制代碼仍然存在,但已經從應用程序轉移到了操作系統提供的底層網絡層中。
韓國檢方已正式起訴姜鐘賢,并扣押搜查Bithumb最大股東Vidente:金色財經報道,今日上午,韓國檢方在對 Bithumb 相關公司涉嫌挪用資金的調查中,對 Bithumb 最大股東 Vidente(持有 Bithumb 34.22% 的股份)進行扣押搜查。
據悉,檢方正在對被稱為姜氏兄妹就涉嫌操縱 Bithumb 股價及挪用資金案進行額外調查,姜鐘賢和其親信趙某已被逮捕,2 月 20 日,韓國檢方已正式起訴姜鐘賢,指控其涉嫌犯有《特定經濟犯罪加重處罰法》中的瀆職、貪污和《資本市場法》中的欺詐交易等罪名。[2023/2/22 12:22:30]
這個模型相當地成功。幾乎任何一個組織都能夠使用商業操作系統附帶的 TCP/IP 協議棧來驅動他們的業務,即使有高性能和高可靠性的要求。
多年以來,計算機變得越來越便宜,并且到處可見,而上面提到的網絡協議棧已被證明是用于可靠連接系統的事實上的工具集。隨著節點和穩定連接的數量越來越多,行業中出現了各種各樣的網絡系統,從細粒度的分布式代理和對象到由較大但重分布式組件組成的面向服務的架構。
不過,為了處理更復雜的問題,需要轉向更加分散的系統(我們通常所說的微服務架構),這在可操作性方面提出了新的要求。下面則列出了一個必須要處理的東西:
① 計算資源的快速提供
② 基本的監控
③ 快速部署
④ 易于擴展的存儲
⑤ 可輕松訪問邊緣
⑥ 認證與授權
⑦ 標準化的 RPC
因此,盡管數十年前開發的 TCP/IP 協議棧和通用網絡模型仍然是計算機之間相互通訊的有力工具,但更復雜的架構引入了另一個層面的要求,這再次需要由在這方面工作的工程師來實現。例如,對于服務發現和斷路器,這兩種技術已用于解決上面列出的幾個彈性和分布式問題。
歷史往往會重演,第一批基于微服務構建的系統遵循了與前幾代聯網計算機類似的策略。這意味著落實上述需求的責任落在了編寫服務的工程師身上。
服務發現是在滿足給定查詢條件的情況下自動查找服務實例的過程,例如,一個名叫 Teams 的服務需要找到一個名為 Players 的服務實例,其中該實例的 environment 屬性設置為 production。你將調用一些服務發現進程,它們會返回一個滿足條件的服務列表。對于更集中的架構而言,這是一個非常簡單的任務,可以通常使用 DNS、負載均衡器和一些端口號的約定(例如,所有服務將 HTTP 服務器綁定到 8080 端口)來實現。而在更分散的環境中,任務開始變得越來越復雜,以前可以通過盲目信任 DNS 來查找依賴關系的服務現在必須要處理諸如客戶端負載均衡、多種不同環境、地理位置上分散的服務器等問題。如果之前只需要一行代碼來解析主機名,那么現在你的服務則需要很多行代碼來處理由分布式引入的各種問題。
斷路器背后的基本思路非常簡單。將一個受保護的函數調用包含在用于監視故障的斷路器對象中。一旦故障達到一定閾值,則斷路器跳閘,并且對斷路器的所有后續調用都將返回錯誤,并完全不接受對受保護函數的調用。通常,如果斷路器發生跳閘,你還需要某種監控警報。
這些都是非常簡單的設備,它們能為服務之間的交互提供更多的可靠性。然而,跟其他的東西一樣,隨著分布式水平的提高,它們也會變得越來越復雜。系統發生錯誤的概率隨著分布式水平的提高呈指數級增長,因此即使簡單的事情,如「如果斷路器跳閘,則監控警報」,也就不那么簡單了。一個組件中的一個故障可能會在許多客戶端和客戶端的客戶端上產生連鎖反應,從而觸發數千個電路同時跳閘。而且,以前可能只需幾行代碼就能處理某個問題,而現在需要編寫大量的代碼才能處理這些只存在于這個新世界的問題。
事實上,上面舉的兩個例子可能很難正確實現,這也是大型復雜庫,如 Twitter 的 Finagle 和 Facebook 的 Proxygen,深受歡迎的原因,它們能避免在每個服務中重寫相同的邏輯。
數據:V神地址在過去20日內向巨鯨地址0x9e92轉入了9300枚ETH:金色財經報道,據 Lookonchain 監測,0xd04d開頭地址在過去20日內向巨鯨地址0x9e92轉入了9300枚ETH(約1116萬美元)。0xd04d開頭可能屬于以太坊創始人Vitalik Buterin,其收到的所有7萬枚ETH均來自于Vb3 ,巨鯨地址0x9e92目前持有17萬枚ETH(約2.59億美元)。[2023/1/19 11:21:25]
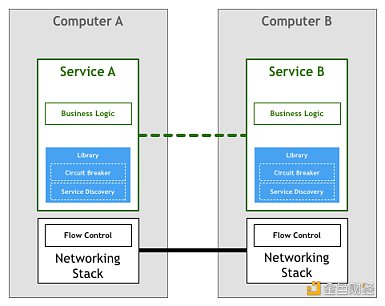
大多數采用微服務架構的組織都遵循了上面提到的那個模型,如 Netflix、Twitter 和 SoundCloud。隨著系統中服務數量的增加,他們發現了這種方法存在著各種弊端。即使是使用像 Finagle 這樣的庫,項目團隊仍然需要投入大量的時間來將這個庫與系統的其他部分結合起來,這是一個代價非常高的難題。有時,代價很容易看到,因為工程師被分配到了專門構建工具的團隊中,但是更多的時候,這種代價是看不見的,因為它表現為在產品研發上需要花費更多的時間。
第二個問題是,上面的設置限制了可用于微服務的工具、運行和語言。用于微服務的庫通常是為特定平臺編寫的,無論是編程語言還是像 JVM 這樣的運行時。如果開發團隊使用了庫不支持的平臺,那么通常需要將代碼移植到新的平臺。這浪費了本來就很短的工程時間。工程師沒辦法再把重點放在核心業務和產品上,而是不得不花時間來構建工具和基礎架構。那就是為什么一些像 SoundCloud 和 DigitalOcean 這樣的中型企業認為其內部服務只需支持一個平臺,分別是 Scala 或者 Go。
這個模型最后一個值得討論的問題是管理方面的問題。庫模型可能對解決微服務架構需求所需功能的實現進行抽象,但它本身仍然是需要維護的組件。必須要確保數千個服務實例所使用的庫的版本是相同的或至少是兼容的,并且每次更新都意味著要集成、測試和重新部署所有服務,即使服務本身沒有任何改變。
類似于我們在網絡協議棧中看到的那樣,大規模分布式服務所需的功能應該放到底層的平臺中。
人們使用高級協議(如 HTTP)編寫非常復雜的應用程序和服務,甚至無需考慮 TCP 是如何控制網絡上的數據包的。這種情況就是微服務所需要的,那些從事服務開發工作的工程師可以專注于業務邏輯的開發,從而避免浪費時間去編寫自己的服務基礎設施代碼或管理整個系統的庫和框架。將這個想法結合到我們的圖表中,我們可以得到如下所示的內容:
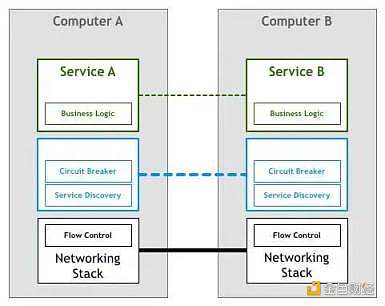
通過改變網絡協議棧來添加這個層并不是一個可行的任務。許多人的解決方案是通過一組代理來實現。這個的想法是,服務不會直接連接到它的下游,而是讓所有的流量都將通過一個小小的軟件來透明地添加所需功能。
在這個領域第一個有記載的進步使用了邊三輪(sidecars)這個概念。「邊三輪」是一個輔助進程,它與主應用程序一起運行,并為其提供額外的功能。在 2013 年,Airbnb 寫了一篇有關 Synapse 和 Nerve 的文章,這是「邊三輪」的一個開源實現。一年后,Netflix 推出了 Prana,專門用于讓非 JVM 應用程序從他們的 NetflixOSS 生態系統中受益。在 SoundCloud,我們構建了可以讓遺留的 Ruby 程序使用我們為 JVM 微服務構建的基礎設施的「邊三輪」:
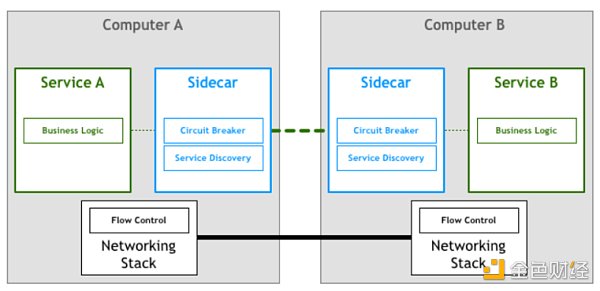
雖然有這么幾個開源的代理實現,但它們往往被設計為需要與特定的基礎架構組件配合使用。例如,在服務發現方面,Airbnb 的 Nerve 和 Synapse 假設了服務是在 Zookeeper 中注冊,而對于 Prana,則應該使用 Netflix 自己的 Eureka 服務注冊表 。隨著微服務架構的日益普及,我們最近看到了一波新的代理浪潮,它們足以靈活地適應不同的基礎設施組件和偏好。這個領域中第一個廣為人知的系統是 Linkerd,它由 Buoyant 創建出來,源于他們的工程師先前在 Twitter 微服務平臺上的工作。很快,Lyft 的工程團隊宣布了 Envoy 的發布,它遵循了類似的原則。
ARK方舟基金賣出Coinbase和Robinhood股票:7月27日消息,ARK方舟基金賣出Coinbase和Robinhood股票。(金十)[2022/7/27 2:40:04]
在這種模式中,每個服務都配備了一個代理「邊三輪」。由于這些服務只能通過代理「邊三輪」進行通信,我們最終會得到類似于下圖的部署方案:
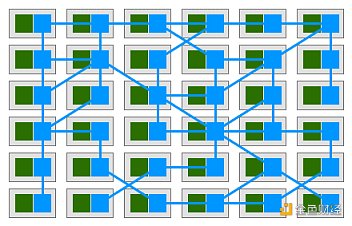
服務網格是用于處理服務到服務通信的專用基礎設施層。它負責通過復雜的服務拓撲來可靠地傳遞請求。實際上,服務網格通常被實現為與應用程序代碼一起部署的輕量級網絡代理矩陣,并且它不會被應用程序所感知。這個定義最強大的地方可能就在于它不再把代理看作是孤立的組件,并承認它們本身就是一個有價值的網絡。
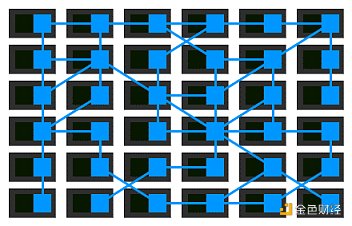
隨著微服務部署被遷移到更為復雜的運行時中去,如 Kubernetes 和 Mesos,人們開始使用一些平臺上的工具來實現網格網絡這一想法。他們實現的網絡正從互相之間隔離的獨立代理,轉移到一個合適的并且有點集中的控制面上來。
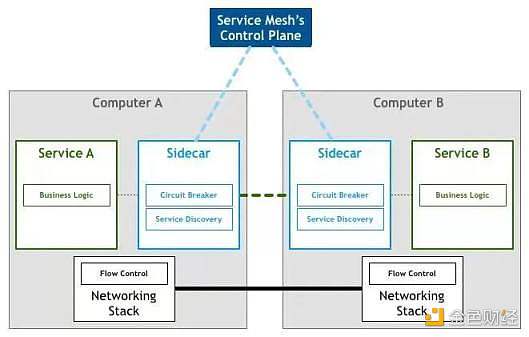
來看看這個鳥瞰圖,實際的服務流量仍然直接從代理流向代理,但是控制面知道每個代理實例。控制面使得代理能夠實現諸如訪問控制和度量收集這樣的功能,但這需要它們之間進行合作:
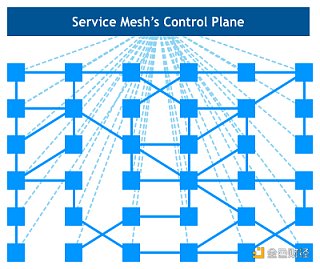
完全理解服務網格在更大規模系統中的影響還為時尚早,但這種架構已經凸顯出兩大優勢。首先,不必編寫針對微服務架構的定制化軟件,即可讓許多小公司擁有以前只有大型企業才能擁有的功能,從而創建出各種有趣的案例。第二,這種架構可以讓我們最終實現使用最佳工具或語言進行工作的夢想,并且不必擔心每個平臺的庫和模式的可用性。
總結一下:隨著 Service Mesh 的發展,傳統業務的一部分確實會向著分布式的趨勢發展。
其次,如果從 Web3 的業務來看,與 Web2.0 不同,Web3 的業務和基礎設施綁定的很深,Web3 也有分布式數據中心的需求。特別是在以太坊轉為 PoS 之后,不需要所有的節點去達成共識,而是 PoS 中的超級節點進行投票,PoW 模式下,所有節點都可以參與驗證,但 PoS 的場景則只有被選出的超級節點可以成為驗證節點,這些超級節點通常是運行著 GNU/Linux。每一次驗證需要超過 2/3 的機器的節點都要參與投票,才能夠通過,假設某項業務全球有幾十個超級節點,一個節點放到德國的 Hetzner 數據中心,一個在法國節點放到 OVH 數據中心,然后日本的節點又是一個當地機房進行托管,
如何保證這些服務器本身的運行狀態是可信的,比如沒有遭到機房管理人員或者其他 Evil Maid(邪惡女仆)的篡改,如果能做到這點那 web3 超級節點的物理服務器可以被扔進這個星球上任何一個數據中心并且放心大膽的運行,畢竟驗證服務器是關系到錢的組件。另外一方面,不同超級節點之間可以使用邦聯化協議或者跨鏈橋的方式進行通信。
然后,我們從商業需求、社會文化、和目前看到的一些跡象來解釋為什么下一代數據中心會呈現分布式:
首先是企業降低成本的需求。很多知名企業開始嘗試自建云,這種自建模式本身就算分布式的呈現。原因主要在于,目前公有云成本極其高,而自建云會顯著降低成本。一個典型的案例就是 Dropbox。Dropbox 通過構建自己的技術基礎設施,在兩年內節省運營成本近 7500 萬美元。從 2015 年開始,Dropbox 開始將其文件存儲服務的用戶從 AWS 的 S3 存儲服務轉移到自己定制設計的基礎設施和軟件上,從 2015 年到 2016 年,這個項目,讓 Dropbox 節省了 3950 萬美元,將「我們的第三方數據中心服務提供商」的支出減少了 9250 萬美元,2017 年,它比 2016 年的數字額外節省了 3510 萬美元的運營成本。
注意,早期的 Dropbox 由于使用了亞馬遜網絡服務,構建起了龐大的用戶群和品牌形象。盡管許多公司仍然樂于向 AWS 支付管理其基礎設施的費用,但是,這種依賴知名云廠商的情況會一直存在嗎?一旦初創公司變成擁有數億用戶的大公司,并且他們已經非常了解計算需求,那么建立完全按照這些需求設計的計算基礎設施可能會更有效率。經過多年的實踐,Dropbox 于 2016 年第四季度完成了所謂的「基礎設施優化」項目。
Dropbox 管理層是這么說的,「我們的基礎設施優化降低了單位成本,并幫助限制了資本支出和相關折舊。結合我們的付費用戶群的同期增長,我們經歷了收入成本的降低,毛利率的增加,以及我們在所呈現期間自由現金流的改善。」
那么,如果 Dropbox 選擇自建基礎設施,這會不會成為行業內的一種趨勢?
其次,從技術的底層來看,數據中心的進化和摩爾定律有一定關聯度,也就是說,芯片性能在持續提升并且價格下降還可以不斷下降。但是,我們也發現,摩爾定律過去 10 年對于性能的增速明顯在下降,AMD EPYC3 造就了單節點性能的一個高峰,原因除了 AMD 的微架構優化不錯外也和用了 TSMC 的 5nm 工藝有關,這會成為一個通用計算的一個岔路口。為什么這么說,首先, EPYC3 的微架構優化不錯且制程也使用了較先進的 5nm 工藝,基于硅的通用計算往后性能提升會極其有限。其次,EPYC3 成本上優勢巨大,不光是對比 Intel 也包括 arm64 平臺。AMD EPYC3 把單計算節點(服務器)性能推上了一個高峰,之前需要 4-7 個機架才能達到的性能,0xide 的服務器一個機架就可以達成,這對于 Web3 的數據中心來說,會極大的降低運維成本。
第三,就如同 BTC 出現是為了反抗金融危機之后的傳統金融系統,數據中心也是一樣。人類長期經歷了數據和業務集中化的年代,對業務的反壟斷和去中心化有著天然的需求。正所謂天下話說天下大勢,分久必合,合久必分,Web1.0 時代本來是去中心化的,但到了 2.0 的年代實際上就是少數的壟斷性科技企業通過使用普通用戶的數據得到了了巨額利潤,Web3 想解決的也是這個方面的問題,而第四代數據中心由于單點芯片技術能達到的程度,原來需要 10 個機柜的性能,現在可能 2 個就搞定了,這樣的話,從技術上去支撐聯邦化數據中心的業務可以說是神助攻。
第四,目前移動數據中心逐漸發展成熟,可以成為 Web3 數據中心業務的擴充。如下圖,我們發現 DC-ITRoom 機架和集裝箱用量在不斷增大,DC-ITRoom 機架和集裝箱是啥呢?其實就算是移動化的數據中心,如果做一個大的活動,活動對數據有要求,就可以使用這種集裝箱式的可移動數據中心。那它和 Web3 的關系何在?在 PoW 的時代,其實就算在證明誰的算力大,那么這種移動化的數據中心可以直接靠數量堆上去給 Web3 的節點驗證提供算力。
不過,我們在理解下一代數據中心時,也要結合區塊鏈的固有特性去考慮。
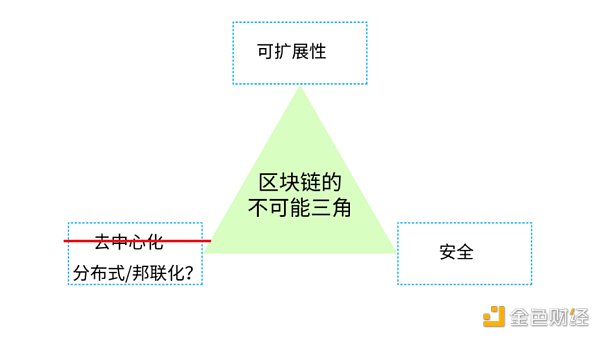
已知常識是,區塊鏈具備不可能三角,這個不可能三角指的是,去中心化、安全、可擴展性這三者是無法同時滿足的,也就是說,任何系統的設計只能滿足其中兩個。比如極端的去中心化方案 BTC(比特幣)和 XMR(門羅)都是以犧牲可擴展性為代價的,這導致 BTC/XMR 技術架構無法提供更復雜的業務,所以對于這類似這兩種方案的業務來說,Layer 2 的存在是必然的,因為需要支持更復雜的業務。
為什么說 BTC 和 XMR 的設計都是極端去中心化的?因為這兩種區塊鏈,首先它們的業務非常簡單且單一,比如 XMR/BTC 都是記賬和轉賬功能 ;其次,每個節點都可以成為驗證方,那也就意味著全網數據都可以保存在每個節點上。
但是,Layer 2 對于安全主要有幾個方面的挑戰:
首先,安全和可擴展性對于去中心化系統也至關重要,超級節點的引入會增加系統安全的風險。舉個例子,PoW 的模式下,以前需要搞定幾萬個節點才能發起攻擊比如 51%。但 PoS 時代,超級節點的誕生讓需要掌控節點數量大大降低,安全存在的隱患也就更大。
其次,跨鏈協議實現中存在缺陷。這個缺陷要怎么理解?其實就是目前例如跨鏈橋的實現中存在 bug,比如 A 到 B 鏈經過跨連橋 C,但 C 在沒有完成 A 和 B 的檢查就把 transaction 放行,那就可能被攻擊者利用去進行無限制轉賬。
第三就是供應鏈安全。主要包括開發人員是否會植入后門以及 build 基礎設施的需要安全加固等考考量因素。
不過,如果犧牲一部分去中心化的特性,采用邦聯化的架構,那這個三角就可以成為可能(也就是可以滿足可擴展性和安全的特性)我們認為,Scalability 和 Security 是不能犧牲的,因為一旦這么做了,復雜業務也無法開展。不過,如果用分布式\邦聯化替代 100 % 的完全去中心化,就會導致技術架構轉變。因為完全去中心化指的是每個節點都有驗證的權利,那即使某幾個節點被攻擊,也只是錢包安全的問題。但如果是 PoS 選出超級節點成為 validator 的節點受了攻擊問題那嚴重性就非常高了。
那么,倘若第四代數據中心真正到來,應用場景又是怎樣的呢?
這里我們舉一個應用場景:
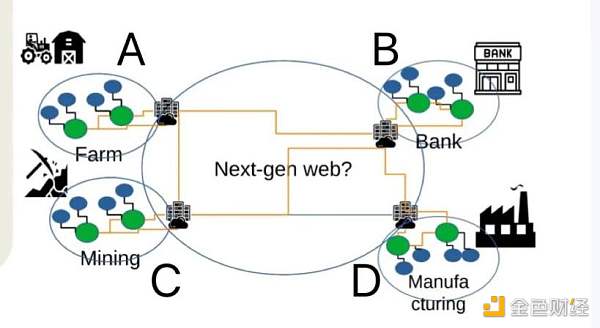
如圖所示,A 為農業小鎮,B 為金融小鎮,C 為礦業小鎮,D 為工廠小鎮,藍色橢圓代表業務節點,綠色橢圓代表邦聯化的服務器,這四個小鎮是互相聯系的,使用分布式 / 邦聯化的數據中心架構。
首先,小鎮數據中心里的各個業務節點,可以根據具體業務需求跟其他小鎮的業務節點進行交互,這種呈現,實質上在極端去中心化和效率之間得到了平衡(PoS 就是極端去中心化和效率之間進行平衡的代表這個平衡,因為 PoW 無法承載復雜的業務)。這也是我們所認為的下一代互聯網(Web3)的主流形態之一。
第二,在分布式賬本(區塊鏈)的上下文中,邦聯化服務器有點類似于超級節點,這種節點需要把自身的安全等級公開,比如 Security Chain 的設計中,是把安全防護等級和日志公布在區塊鏈上。
第三,四個小鎮使用了第四代數據中心的架構,服務器單節點都具備高性能特征(比如搭載 AMD EPYC3 的服務器每個機柜可提供超過 4000 個 CPU 核),這讓原本需要 10 個機柜的運算能力現在大概只需要 2 個。
第四, 四個小鎮使用的服務器固件是開源實現,開源雖然不能直接保證安全,但其可審計性可以降低后門的風險。
第五,四個小鎮的用戶如果把服務器部署在自己的家里,那么安全性會有保證,至少 Evil Maid 的攻擊風險會降低,但如果要讓用戶任意的把物理服務器放置在 4 個小鎮的任意數據中心中的話,那就需要硬件級別的安全特性,以保證用戶可以隨時通過遠程證明進行驗證自己的機器是否處于「預期」的運行狀態。
首先,目前的技術進程已經逐步滿足當年早期 0ldsk00l 黑客和密碼朋克對未來互聯網烏托邦式的構想,因為無論是密碼朋克宣言,自由軟件運動,到后期的開源軟件和開源硬件商業化和加密貨幣,這些技術和思想也逐步開始加速了 Web3 時代的發展。
其次,近期 ETH 合并,也代表嘗試用主鏈 +layer 2 方式構建復雜業務時代的結束,在此我們從技術和生態的角度,大膽的預測一下未來可能面臨的機遇和挑戰:
ETH 的主鏈和 layer 2 的邊界會變得模糊,或者需要重新定位。
如果 BTC 能繼續保持在人們心中的黃金共識,那 BTC 會承載大部分 PoW 的工作,如果共識把隱私納入考量部分算力會轉向 XMR/ZEC.
承載復雜業務的 Web3 顯然逐步走向了邦聯化,而非完全的去中心化的路線,任何形式的超級節點會以幾種方式存在:
當前的主流是跨鏈橋。
邦聯化標準協議的出現,因為需要協調眾多的玩家生態,從傳統的邦聯化系統比如 email 或者 XMPP 可以看到這種模式在一定程度上會導致發展緩慢。
打造 JIT 解釋器或者 LLVM IR 重構跨鏈協議以降低生態的開發成本。
有不少同學都預測未來一定會把大量的超級節點從公有云(主要是 AWS)轉移到數據中心,這樣可以規避一定程度的安全風險,但依然面臨大量的來自基礎架構的安全風險,比如 OS(操作系統層面)和 below-OS(操作系統以下的層面)。
基于 ETH 的生態會更多元化,而下一代數據中心會成為一大助力,讓我們拭目以待。
阿法兔
個人專欄
閱讀更多
財經法學
成都鏈安
金色早8點
Bress
鏈捕手
PANews
Odaily星球日報
目前許多主流敘事認為,以區塊鏈技術為基礎構建的 Web3 產品,能夠通過發行代幣賦予用戶以真正的資產所有權.
1900/1/1 0:00:00文:Alex Reeve 來源:Coinbase 為了給世界創建一個開放的金融系統,我們需要確保每個人都可以使用web3.
1900/1/1 0:00:00正如交易員所說,預測底部就像試圖抓住一把落下的刀。觸底一詞很容易被誤解,因為它并不一定意味著價格走勢和加密貨幣市場的整體情緒會突然轉為積極.
1900/1/1 0:00:00羅馬不是一日建成的,元宇宙也一樣。面對鋪面而來的元宇宙概念,很多人還一頭霧水。如果我們把視野拔高,以近40年時間軸的方式來看,或許能把元宇宙看得更清楚.
1900/1/1 0:00:00撰文:Jake、Stake編譯:aididiaojp.eth,Foresight News市場已陷深熊,許多 DAO 及其貢獻者開始懷疑他們能否度過這漫長的加密寒冬.
1900/1/1 0:00:00從去年開始,隨著NFT的大火,各大品牌入局NFT的消息也不絕于耳。比如Tiffany面向CryptoPunk持有者推出NFTiffs NFT;耐克旗下加密時尚品牌RTFKT發行了CloneX N.
1900/1/1 0:00:00


